Волчьи ямы опережающей записи
Начиная с K5 процессоры серии x86 используют прозрачную буферизацию записи (см. "Кэш – принципы функционирования. Буфера записи"), причем, буфера записи доступны не только на запись, но на чтение. То есть, результат работы команды становится доступным сразу же, как только он попадает в буфер,– дожидаться завершения его выгрузки в кэш-память нет никакой нужды! Очевидно, что такой трюк, именуемый разработчиками процессоров опережающий записью (Store-Forwarding), значительно сокращает время доступа к данным.
Рассмотрим это на следующем примере. Пусть у нас имеется цикла вида.
for(a = 0; a < BLOCK_SIZE; a += sizeof(tmp32))
{
p[a] += tmp_1;
tmp_2 -= p[a];
}
Вместо того, чтобы гонять данные по "большому кругу кровообращения": вычислительное устройство à
блок записи à
кэш à
блок чтения à
вычислительное устройство, процессор AMD Athlon направляет данные по "малому кругу кровообращения" вычислительное устройство à
буфер записи à
вычислительное устройство. Как видно, малый круг намного короче! Pentium–процессоры судя по всему ведут себя точно так же, хотя ничего вразумительного на этот счет в документации не говорится.
Разумеется, буферизации записи присущи определенные ограничения и она эффективная лишь в тех случаях, когда читаются именно те данные, которые были записаны. В противном случае, процессор выставляет пенальти и быстродействие программы значительно падает.
Продемонстрируем это на следующем примере (см. рис. 0х17 слева):
*(int *)((int)p) = x; // запись данных в буфер
y = *(int *)((int)p + 2); // байтов [p+2; p+4] нет в буфере
Грубо говоря, мы записываем в буфер ячейки 0, 1, 2 и 3, а затем запрашиваем ячейки 2, 3, 4 и 5. Легко сообразить, что ячеек 4 и 5 просто нет в буфере и для их загрузки процессору необходимо обратиться к кэшу. Но ведь в кэше еще нет ячеек 2 и 3, – т.к. они не успели покинуть буфер!
Доподлинно неизвестно как процессор выходит из этой ситуации. Возможно, часть ячеек он считывает из буфера, а часть – из кэша и объединяет обе "половинки" в одну. Возможно (и более вероятно на мой взгляд), процессор сбрасывает содержимое буфера в кэш и уже оттуда безо всяких ухищрений извлекает запрошенные данные.
Но, так или иначе, все это требует дополнительных тактов, снижающих производительность. (На P-III величина пенальти составляет шесть тактов, а на AMD Athlon – десять).
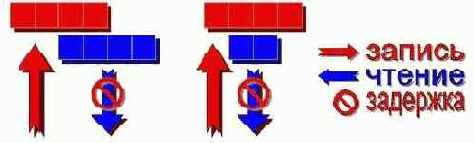
Рисунок 33 0х017 Возникновение задержки при перекрытии областей чтения/записи
Другое ограничение. Даже если запрошенные данные целиком содержатся в буфере, но адреса читаемой и записываемой ячеек не совпадают, – все равно возникает задержка, т.к. процессору приходится выполнять определенные преобразования, отсекая "лишние" биты из записанного результата (см. рис. 0х17 справа).

Рисунок 34 0х018 Возникновение задержки при несоответствии разрядности данных
Наконец, если адреса ячеек совпадают, но они имеют различную разрядность, – задержки опять-таки не миновать. Логично, что если размер записываемой ячейки меньше читаемой (см. рис. 0х18 справа), – только часть запрашиваемых данных попадает в буфер, а все остальное содержится в кэше, т.е. ситуация сводится к рассмотренной выше.
Природу задержки, возникающий при записи ячейки большей разрядности (см. рис. 0х18 слева), понять сложнее. Несмотря на то, что данные непосредственно извлекаются из буфера, минуя кэш, отсечение лишних битов требует какого-то времени (по меньшей мере одного такта)…
То же самое справедливо и для нескольких коротких записей, перекрываемых последующим длинным чтением. Разберем следующий пример:
*(char *)((int)p + 0) = 'B';
*(char *)((int)p + 1) = '0';
*(char *)((int)p + 2) = 'F';
*(char *)((int)p + 3) = 'H';
BOFH
= *(int *)((int)p
+ 0); // ß задержка! читаются не те же самые данные,
// которые только что были записаны
На первый взгляд, все здесь вполне корректно, – ведь запрашиваемые данные целиком содержатся в буфере записи. Тем не менее задержка в шесть тактов все равно возникает, – ведь записываемые и читаемые ячейки имеют различную разрядность. Попросту говоря, загружаются отнюдь не те же самые данные, которые только что были записаны! Буфер записи адресуется совсем не так, как кэш-память, и процессор не может мгновенно установить: расположены ли записываемые байты в соседних ячейках или нет.
Отсюда правило. Чтение данных, следующее за их записью, должно иметь тот же самый стартовый адрес и не большую, а лучше такую же точно разрядность. Поэтому, при возможности лучше вообще не работайте со смешанными типами данных (например, байтами и двойными словами), а сводите их к единому типу наибольшей разрядности.
Если же прочесть небольшую порцию только что записанных данных просто жизненно необходимо, – воспользуйтесь, как и рекомендует Intel, битовыми операциями: "If it is necessary to extract a non-aligned portion of stored data, read out the smallest aligned portion that completely contains the data and shift/mask the data as necessary. The penalty for not doing this is much higher than the cost of the shifts".
Допустим, не оптимизированный пример выглядел так:
// не оптимизированный код
for(a = 0; a < BLOCK_SIZE; a += sizeof(int))
{
*(int *)((int)p + a) += x;
y += *(char *)((int)p + a + 2));
}
Выделенная жирным шрифтом строка навлекает страшный гнев процессора и становится самым узким местом в цикле.
Попробуем исправить проблему так:
// оптимизированный код
for(a = 0; a < BLOCK_SIZE; a += sizeof(int))
{
*(int *)((int)p + a)+= x;
tmp = *(int *)((int)p + a); // читаем во временную переменную те же самые данные
x += ((tmp & 0x00FF0000) >> 0x10); // "вручную" выкусываем нужный нам ячейку
}
Вопреки заявлениям Intel, на P- III мы получим даже худшее быстродействие по сравнению с первоначальным вариантом! Остается лишь гадать, кто ошибся: парни из Intel или мы? Быть может, на P-4 расклад вещей окажется совсем иной и ручные битовые махинации возьмут верх над не оптимизированным вариантам, но, по любому, учитывая, что ваша программа планирует исполняться не только на P-4, но и на младших моделях x86–процессоров, не слишком-то закладывайтесь на эту рекомендацию.
До сих мы говорили о записи/чтении одних и тех же данных. Однако, процессор, проверяя наличие запрашиваемых данных в буфере, анализирует не все биты адреса, а только те из них, которые "отвечают" за выбор конкретной кэш-линейке в кэш-памяти первого уровня (так называемые установочные адреса). Отсюда следует, что если адреса записываемых/читаемых ячеек кратны размеру кэш-банка (который можно вычислить поделив размер кэша на его ассоциативность), процессор дезорганизуется и не может определить: какую именно порцию данных ему следует извлекать. Возникает вынужденная задержка на время, пока "одноименные" ячейки не будут выгружены из буфера записи в кэш первого уровня, на что уходят те же самые шесть (P-III) или десть (AMD Athlon) тактов процессора.
Рассмотрим следующий пример:
*(int *)((int)p) = x;
*(int *)((int)p + L1_CACHE_SIZE/L1_CACHE_WAY_ASSOCIATIVE) = y;
z = *(int *)((int)p); // ß задержка
Поскольку, записываемые данные имеют идентичные установочные адреса, процессор не может осуществить опережающее чтение из буфера и вынужден дожидаться пока обе ячейки не попадут в кэш. Закладываясь на наименьший возможный размер кэш-банка (2 Кб на P-4), располагайте все интенсивно "передергиваемые" переменные в пределах одного килобайта.
Следует заметить, что все вышесказанное не распространяется на запись, следующую за чтением, т.е. код следующего вида будет исполняться вполне эффективно:
for(a = sizeof(int); a < BLOCK_SIZE; a += sizeof(int))
{
x += *(char *)((int)p + a - (sizeof(int)/2));
*(int *)((int)p + a) += y;
}
И в заключении главы – наш традиционный эксперимент, позволяющий количественно оценить степень падения производительности при неправильном обращении к данным. Для наглядности мы последовательно переберем все шесть комбинаций (см. листинг mem.stail.c), упомянутых в руководстве по оптимизации от Intel (кстати, руководство по оптимизации от AMD крайне поверхностно и туманно освещает эту проблему, поэтому даже если вы убежденный поклонник AMD не побрезгуйте обратится к Intel, тем более, что в этом вопросе оба процессора ведут себя одинаково).
// выделяем
память
p = (int*)_malloc32(BLOCK_SIZE);
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Long Write/Long Read(same addr)
*
----------------------------------------------------------------------- */
for(a = 0; a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(int *)((int)p + a) = tmp32;
tmp32 += *(int *)((int)p + a);
}
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Short Write/Long Read (same addr)
*
----------------------------------------------------------------------- */
for(a = 0; a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(char *)((int)p + a) = tmp8;
tmp32 += *(int *)((int)p + a);
}
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Short Write/Long Read (overlap space)
*
----------------------------------------------------------------------- */
for(a = sizeof(tmp32); a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(char *)((int)p + a + (sizeof(tmp32)/2)) = tmp8;
tmp32 += *(int *)((int)p + a);
}
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Long Write/Short Read (same addr)
*
----------------------------------------------------------------------- */
for(a = 0; a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(int *)((int)p + a) = tmp32;
tmp8 += *(char *)((int)p + a);
}
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Long Write/Short Read (overlap space)
*
----------------------------------------------------------------------- */
for(a = sizeof(tmp32); a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(int *)((int)p + a) = tmp32;
tmp8 += *(char *)((int)p + a + (sizeof(tmp32)/2));
}
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* Long Write/Long Read (overlap space)
*
----------------------------------------------------------------------- */
for(a = sizeof(tmp32); a < BLOCK_SIZE; a += sizeof(tmp32))
{
*(int *)((int)p + a) = tmp32;
tmp32 += *(int *)((int)p + a - (sizeof(tmp32)/2));
}
Листинг 14 [Cache/mem.stail.c] Демонстрация возникновения задержек памяти при записи/чтении данных различного размера
Результат прогона этой программы на процессорах AMD Athlon 1050 и P-III 733 представлен ниже. При условии, что обрабатываемый блок не превышает размера кэша первого (второго уровня), попытка чтения отсутствующих в буфера данных приводит к пяти-шести кратному падению производительности (см. рис. graph 05)!
На P-4 (если верить его разработчикам) величина пенальти еще больше. Намного больше, вот цитата из руководства: "The performance penalty from violating store-forwarding restrictions was present in the Pentium II and Pentium III processors, but the penalty is larger on the Pentium 4 processor" и дальше "
Приятное исключение составляет чтение маленькой порции данных после записи большой.
Если их адреса совпадают, время доступа к ячейке увеличивается "всего" в полтора раза.
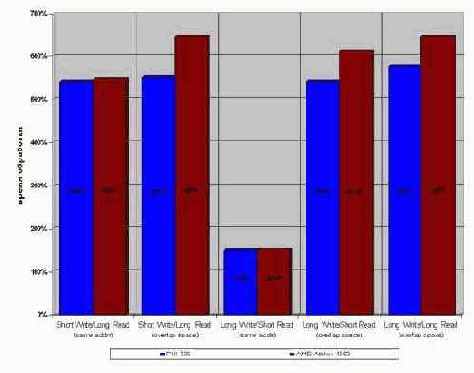
Рисунок 35 graph 05 Возникновение задержек при обработке данных различной разрядности (в кэше первого/второго уровня)
Вне кэша. При выходе за пределы кэш-памяти второго уровня картина существенно изменяется. Штрафные санкции снижаются до не таких уж значительных полутора-трех крат, а короткое чтение после длинной записи на P-III (и – предположительно – на P-II и P-4) исполняется и вовсе без издержек! Впрочем, не стоит обольщаться, – AMD Athlon не простит вам подобных вольностей и накажет двух кратным падением производительности.
С другой стороны, преобразование данных к единому типу путем расширения их до наибольшей разрядности обернется еще большими потерями, – ведь удельное время доступа к ячейкам стремительно растет с увеличением размера обрабатываемого блока.
Таким образом: универсальной стратегии работы с разнотипными данными нет. Решайте сами, что лучше в каждом конкретном случае: мириться со штрафными задержками или возросшей потребностью в памяти.
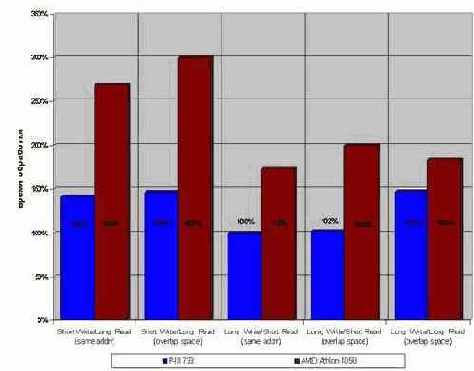
Рисунок 36 graph 06 Возникновение задержек при обработке данных различной разрядности, находящихся в основной памяти