Волчьи ямы опережающей записи II
Итак, как мы уже знаем, при попытке записи в ячейку, отсутствующую в кэш-памяти первого уровня, процессор временно сохраняет записываемые данные в одном из свободных буферов (конечно, если таковые есть), а затем при первой же возможности выгружает их в кэш первого и/или второго уровня.
Чтение данных, находящихся в буфере, осуществляется по крайней мере на один такт быстрее, чем обращение к кэшу первого уровня, к тому же буфера имеют значительно больше портов, чем кэш и могут обрабатывать более двух запросов одновременно (хотя, буфера записи процессора AMD K5 имели всего один-единственный порт). Как это можно использовать на практике?
На P6 и K6 следующий код будет исполняться предельно быстро независимо от того, присутствует ли ячейка *p в сверхоперативной памяти или нет:
*p = a;
b = p*;
Тем не менее, использование буферов записи таит в себе одну очень коварную опасность. Рассмотрим следующий пример, на первый взгляд как будто бы полностью повторяющий предыдущий:
*p = a;
f = (sin(x) + con(y)) / z;
b = p*;
Да, команды записи и чтения данных уже не прижаты друг к другу, а разделены некотором количеством "посторонних" инструкций. Предположим, что компилятор сгенерировал наиглупейший код, сохраняющий результаты всех четырех вычислений в промежуточных переменных. Предположим, что все переменные (включая f) отсутствуют в кэше и претендуют на различные буфера записи. Тогда, между записью ячейки *p и чтением ее содержимого происходит заполнение всего лишь пяти буферов, и судя по всему *p еще находится в буфере.
А вот и нет! Кто вам это обещал?! Разработчики процессора? Отнюдь! Буфера записи, в отличии от кэш-памяти, склонны к самопроизвольному опорожнению с переносом (именно переносом, а не копированием!) своего содержимого в кэш первого и/или второго уровня. Рассматриваемый нами пример кода неустойчив, поскольку скорость его выполнения варьируется в зависимости от того, успел ли процессор выгрузить буфера или нет.
Попросту говоря, производительность такого кода определяется "настроением" процессора и различные прогоны могут показать весьма неодинаковые результаты.
Причем, если на K6 содержимое буферов выгружается в кэш первого уровня, откуда данные могут быть считаны всего за один такт, на P6 в этой ситуации возникает кэш-промах и процессор вынужден обращаться к кэшу второго уровня, что будет стоить многих тактов.
В данном случае проблемы легко избежать перегруппировкой команд, – переместив вычислительную операцию на одну строчку вверх или вниз, – мы добьемся спаривания команд записи/чтения и гарантировано избежим преждевременного вытеснения буферов. Но такое решение не всегда достижимо. Команды могут иметь зависимость по данным или вообще находится в различных функциях, а то и потоках. Как быть тогда? Откроем, например, уже упомянутое руководство по оптимизации от Ангера Фрога ("How to optimize for the Pentium family of microprocessors" by Agner Fog) и найдем в главе, посвященной кэш-памяти следующие строки:
"When you write to an address which is not in the level 1 cache, then the value will go right through to the level 2 cache or to the RAM (depending on how the level 2 cache is set up) on the PPlain and PMMX. This takes approximately 100 ns. If you write eight or more times to the same 32 byte block of memory without also reading from it, and the block is not in the level one cache, then it may be advantageous to make a dummy read from the block first to load it into a cache line. All subsequent writes to the same block will then go to the cache instead, which takes only one clock cycle. On PPlain and PMMX, there is sometimes a small penalty for writing repeatedly to the same address without reading in between.
On PPro, PII and PIII, a write miss will normally load a cache line, but it is possible to setup an area of memory to perform differently, for example video RAM (See Pentium Pro Family Developer's Manual, vol. 3: Operating System Writer's Guide").
("Когда на Pentium- просто или Pentium MMX вы записываете данные, отсутствующие в кэш-памяти первого уровня, они будут помещены в кэш второго уровня или основную оперативную память (в зависимости от того: наличествует ли кэш второго уровня или нет). Эта операция занимает приблизительно 100 нс. Если вы обращайтесь на запись восемь или более раз (именно раз, а не байт, как сказано в популярном переводе Дмитрия Померанцева) к одному и тому же 32-байтовому блоку памяти без чтения чего бы то ни было оттуда, и данный блок памяти отсутствует в кэше первого уровня, было бы недурственно предварительно прочитать любую ячейку блока, загружая тем самым его в кэш первого уровня. Все последующие операции записи данного блока будут записываться в кэш первого уровня, что займет всего один такт. На Pentium-просто и Pentium MMX при многократной записи данных по одному и тому же адресу иногда возникают небольшие задержки, если эти данные не будут востребованы.
На Pentium Pro, Pentium-II и Pentium-III промах записи обычно загружает соответствующую кэш-линейку, но если это возможно, установите область памяти для предотвращения различий, например видеопамять (см. "Семейство-Pentium Pro Справочник разработчика. Том 3. Руководство создателям операционных систем").
Выделенное курсивом предложение написано довольно неуверенным тоном (похоже Ангер Фрог и сам его не понимал). Итак, начинаем лексический анализ. "Normally load a cache line" – можно перевести двояко. "нормально загружает" (т.е. самостоятельно загружает без дураков) или же "обычно загружает" (т.е. может загрузить, а может нет). Судя по всему, Ангер Фрог подразумевал последний вариант. Действительно, в зависимости от состояния соответствующих атрибутов страницы, кэширование записи может быть как разрешено, так и нет. Вот например, в области видеопамяти оно уж точно запрещено, ведь в противном случае обновление изображения происходило бы не в момент записи, а спустя неопределенное время после вытеснения данных из кэша первого уровня, что вряд ли кого могло устроить.
Вот Фрог и советует: убедитесь, что обрабатываемая область памяти разрешает кэширование…
Между тем, это только часть истины, – Ангер Фрог совсем забыл о буферизации. На самом деле, и на P-Pro, и на P-II, и на P-III промах записи не загружает кэш линейку! (Исключение составляет запись расщепленных данных). На K6/Athlon промах записи так же не приводит к немедленной загрузке кэш-линейки, но поскольку содержимое буферов вытесняется в кэш первого уровня, с некоторой натяжкой можно сказать, что такая загрузка все-таки происходит.
Поэтому, к современным процессорам применимы те же самые рекомендации, что и к Pentium-просто и Pentium MMX. Покажем их живое воплощение на практике:
volatile trash;
trash = *p;
*p = a;
f = (sin(x) + con(y)) / z;
b = *p;
Что изменилось? Обратите внимание на выделенную жирным шрифтом строку, загружающую содержимое записываемой ячейки в неиспользуемую переменную. Такой трюк практически не снижает производительности (т.к. процессоры P6 и K6 могут дожидаться загрузки ячейки из оперативной памяти параллельно с ее записью), но гарантирует, что содержимое буферов к моменту обращения к ним, не будет вытеснено дальше кэша первого уровня. А кэш первого уровня – он всегда под рукой и его чтение не займет много времени.
Как всегда здесь не обходится без тонкостей. При загрузке данных в неиспользуемую переменную оптимизирующий компилятор может проигнорировать бессмысленное с его точки зрения присвоение и… тогда у нас ничего не получится. Один из способов запретить компилятору самовольничать – объявить переменную как volatile.
Экспериментальное подтверждение самопроизвольной выгрузки буферов. Теперь, после надлежащей теоретической подготовки, имеет смысл исследовать процесс выгрузки буферов что называется "в живую". Конкретно нас будет интересовать какой именно промежуток времени записываемые данные проводят в буферах, в каком порядке и с какой скоростью они вытесняются оттуда.
Но ведь буфера записи полностью прозрачны для программиста и нам не предоставлено абсолютно никаких рычагов управления! Хорошо, будем рассматривать буфер как "черный ящик" со входом и выходом.
Как узнать что у него внутри? Непосредственно задачу решить невозможно, но мы вполне в состоянии посылать этому ящику запросы и засекать время их выполнения. Останется лишь сопоставить несколько очевидных фактов и прийти к определенным заключениям. Попросту говоря: если данные считываются практически мгновенно – они безусловно все еще находятся в буфере. Чуть большая задержка укажет на то, что данных в буфере уже нет и их следует искать в кэше первого уровня. Наконец, резкое увеличение времени доступа означает, что данные выгружены непосредственно в кэш второго уровня.
Как мы будем действовать? Последовательно записывая все большее и большее количество ячеек с последующим обращением к первой из них, мы рано или поздно столкнемся с внезапным паданием производительности. Это и будет обозначать, что ячейка, содержимое который мы пытаемся прочесть, по тем или иным причинам, покинула застенки буферов и отошла в мир иной. Так мы узнаем стратегию выгрузки буферов: выгружаются ли они в "фоновом" режиме или выгрузка происходит лишь при переполнении буферов.
Вообще-то, тестовую программу можно было бы написать и на чистом Си, но на этом пути притаилось множество трудностей. Си не поддерживает циклических макросов, а, значит, не позволяет автоматически дублировать команды записи заданное число раз. Если же выполнять запись в цикле, мы сразу проиграем в точности измерений. Во-первых, накладные расходы на организацию цикла сравнимы со временем загрузки данных из кэша первого уровня. Во-вторых, нельзя быть уверенным, что код, сгенерированный компилятором, не содержит лишних обращений к памяти. И, в-третьих, параллельно с обработкой ветвлений могут выгружаться буфера.
Да простят меня прикладные программисты, но все-таки я остановлю свой выбор на ассемблере. К слову сказать, приведенные ниже листинги, достаточно подробно комментированы и разобраться в алгоритме их работы навряд ли будет стоить большого труда. И еще, не смейтесь, пожалуйста, но одна из частей программы реализована в виде… пакетного файла.
Да-да, не него возложена миссия
___промежуток времени, в течении которого записываемые данные еще можно надеяться обнаружить в буферах, а так же
; N_ITER EQU ? ;// <-- !auto gen!
; /*--------------------------------------------------------------------------
; *
; * макрос, автоматически дублирующий свое тело N раз
; *
; ---------------------------------------------------------------------------*/
STORE_BUFF MACRO N
_N = N
_A = 0
WHILE _A NE _N
MOV [EBX+32*_A],ECX; <- *(int *)((int)p + 32 * _A) = x;
_A = _A + 1
ENDM
ENDM
; /*--------------------------------------------------------------------------
; *
; * ДЕМОНСТРАЦИЯ ВЫГРУЗКИ БУФЕРОВ ВО ВРЕМЕЯ ЗАНЯТОСТИ ШИНЫ
; *
; ---------------------------------------------------------------------------*/
STORE_BUFF N_ITER ; *p+00 = a; <- заполняем буфера записи, записывая
; *p+32 = a; каждый раз ячейку в новый буфер
; *p+64 = a; Буфера выгружаются параллельно с
; .......... записью. Чтобы доказать это мы....
MOV EDX, [EBX] ; b = *p; <- ...мы обращаемся к самому первому
; записанному буферу; если он еще
; не выгружен, - его содержимое
; считается максимально быстро;
; в противном случае возникнет зад.
ADD EBX, 32*N_ITER; <- смещаем указатель на след. буфера
Листинг 15 [Cache/store_buf.xm] Ядро программы, демонстрирующей выгрузку одних буферов записи параллельно с заполнением других
; N_ITER EQU ? ;// <-- !auto gen!
; /*--------------------------------------------------------------------------
; *
; * макрос, автоматически дублирующий свое тело N раз
; *
; ---------------------------------------------------------------------------*/
STORE_BUFF MACRO N
_N = N
_A = 0
WHILE _A NE _N
NOP <- ТЕЛО МАКРОСА
_A = _A + 1
ENDM
ENDM
; /*--------------------------------------------------------------------------
; *
; * ДЕМОНСТРАЦИЯ ВЫГРУЗКИ БУФЕРОВ ВО ВРЕМЕНЯ ПРОСТОЯ ШИНЫ
; *
; ---------------------------------------------------------------------------*/
MOV [EBX], ECX ; *p = a; <- тут мы записываем в *p некое значение
; <- записываемое значение в первую очередь
; <- попадает в буфер записи (store buffers)
STORE_BUFF N_ITER ; ... <- один или несколько NOP
; ... параллельно с их выполнением содержимое
; ... буферов вытесняется в кэш первого (AMD)
; ... или второго (Intel) уровней
MOV EDX, [EBX] ; b = *p; <- читаем содержимое ячейки *p
; если к этому моменту соответствующий ей
; буфер еще не вытеснен, то она причтется
; максимально быстро; в противном же
; случае возникнет задержка
ADD EBX, 32 ; (int)p+32; <- смещаем указатель на след. буфер
Листинг 16 [Cache/store_buf_nop.xm] Ядро программы, демонстрирующей выгрузку буферов во время простоя шины
Результаты прогонов программы на процессорах P-III и AMD Athlon представлены на диаграмме graph 0x013. Наше обсуждение мы начнем с характера кривой зависимости времени загрузки данных от количества команд записи. Кривая P-III изображена жирной линией, выделенной синим цветом. Смотрите, – после семи команд записи время загрузки данных без всяких видимых причин возрастает с ~35 до ~150 тактов, т.е.
в четыре с небольшим раза. Это говорит о том, что первая из записанных ячеек уже покинула буфер и "отлетела" в кэш второго уровня. Она сделала это несмотря на то, что свободные буфера еще не были исчерпаны! Тем самым, мы убедительно доказали, что буфера могут выгружаться и самопроизвольно, а не только при переполнении их. Приняв за время выполнения операции записи один такт, мы сможем оценить приблизительное время выгрузки содержимого перового из буферов. Оно, как нетрудно установить составляет 7±1 тактов.
Последующие три замера показывают практически идентичное время прогона, но затем кривая делает легкий взмах вверх, образуя своеобразную ступеньку. О чем она говорит? По всей видимости, к этому моменту завершает свою выгрузку второй буфер и, вследствие занятости шины, чтение ячеек из кэша второго уровня испытывает некоторые задержки.
Следующая ступенька наблюдается на четырнадцати операциях записи, что и не удивительно, т.к. с этого момента начинается острая нехватка свободных буферов (на P-II/P-III всего 12 буферов плюс два уже освободившихся – итого четырнадцать) и каждая последующая запись обходится приблизительно в семь дополнительных тактов, требующихся для выгрузки содержимого хотя бы одного из буферов. Неудивительно, что производительность стремительно падает, прямо как рубль в печально памятные дни августовского кризиса.
Теперь запустим второй вариант программы, который выполняет всего одну-единственную запись, затем выдерживает короткую паузу, скармливая процессору некоторое количество команд-пустышек, после чего проверяет наличие записанных данных в буфере. Оказывается, как это подтверждает тонкая голубая линия, опорожнение буферов происходит и в данном случае, причем, приблизительно за тоже самое время, что и в предыдущей программе (процессоры P-II/P-III способны выполнять до трех машинных команд NOP за каждый такт, поэтому, результаты замеров следует разделить на три).
Поскольку, время записи данных в кэш второго уровня на P-III составляет всего лишь два такта, напрашивается интересный вывод: содержимое буферов выгружается отнюдь не при первой же возможности (ну да, увидел, что шина свободна и как идиот побежал), а согласно внутреннему таймеру.
Я не уверен, что продолжительность проживания данных в буферах записи на всех процессорах идентична, но во всяком случае, мы установили порядок этой величины. Как нетрудно видеть, он заметно короче времени выполнения многих вычислительных команд, поэтому, наше интуитивное предположение о нежелательности разделения команд записи и чтения, полностью подтвердилось.
Рассмотрим теперь как реализован механизм буферизации записи в процессоре AMD Athlon (коричневая кривая). Сразу же бросается в глаза, что за счет выгрузки содержимого буферов в кэш первого, а не второго (как на P-II/P-III) уровня, Athlon не имеет проблем с обвальным падением производительности. За счет этого сокращено и время выгрузки буферов. Причем, Athlon, судя по всему, не выгружает буфера вплоть до тех пор, пока в этом не возникнет несущей необходимости.
Правда, наблюдается трудно объяснимый "пик" кривой, отражающий значительное увеличение времени доступа при объединении семнадцати операций записи. Именно семнадцати! Обработка шестнадцати или восемнадцати операций записи не вызывает никаких проблем и "послушно" ложиться на гладкую кривую. Почему так происходит – трудно сказать… Требуются дополнительные исследования (быть может позже – по втором издании настоящей книги вы и встретите объяснение, пока же спишем это на ошибку разработчиков процессора).
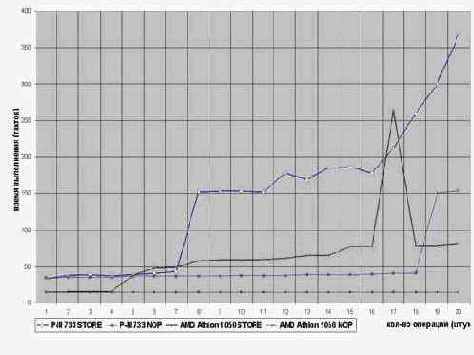
Рисунок 37 graph 0x013 Демонстрация выгрузки буферов записи