Стратегия оптимального выравнивания
Если обращение к данным, пересекающим кэш-строку, происходит лишь эпизодически– никакого "криминала" в этом нет, и накладными расходами на дополнительную задержку можно смело пренебречь. Никакой осязаемой выгоды от выравнивания таких переменных мы все равно не получим.
Интенсивно используемые переменные
(например, счетчики цикла) – дело другое. В этом случае потери производительности скорее всего окажутся весьма велики, и по меньшей мере неразумно закрывать на это глаза! Чтобы окончательно убедиться в этом, запустим следующий контрольный пример, использующий в качестве счетчика цикла 32-разрядную переменную, смещенную на 62 байта от начала, гарантируя тем самым ее расщепление и на P?II/P-III, и на AMD Athlon.
#define N_ITER 1000 // кол-во итераций цикла
#define
_MAX_CACHE_LINE_SIZE 64 //максимально возможный размер кэш-линии
#define UN_FOX (*(int*)((int)fox + _MAX_CACHE_LINE_SIZE - sizeof(int)/2))
#define FOX (*fox) // определение выровненного (FOX) и
// не выровненного (UN_FOX) счетчиков
// выделяем память
fox = (int *) _malloc32(MAX_CACHE_LINE_SIZE*2);
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ ВАРИАНТ
* (счетчик цикла не разбивает кэш-строку)
*
------------------------------------------------------------------------*/
for(FOX = 0; FOX < N_ITER; FOX+=1) c++;
/*------------------------------------------------------------------------
*
* ПЕССИМИЗИРОВАННЫЙ ВАРИАНТ
* (счетчик цикла разбивает кэш-строку)
*
------------------------------------------------------------------------*/
for(UN_FOX = 0; UN_FOX < N_ITER; UN_FOX+=1) c++;
Листинг 5 [Cache/align.for.c] Демонстрация последствий использования расщепленного счетчика цикла
Прогон программы показывает (см. рис graph 0x009), что на P-III 733 расщепленный счетчик цикла снижает производительность практически в пять раз, а на AMD Athlon падение производительности не достигает и двух крат, подтверждая тем самым что Athlon – чрезвычайно непритязательный к выравниванию процессор.
И, если бы мир ограничивался одним Athlon'ом – данные можно было бы вообще не выравнивать (шутка).
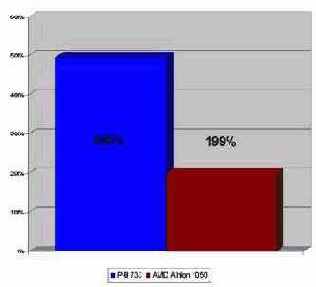
Рисунок 25 graph 0x009 Снижение производительности при обработке расщемленных данных
Обработка массивов. Несколько иначе обстоят дела с последовательной обработкой массивов данных. Этот вопрос мы уже рассматривали в первой части настоящей книги, но тогда речь шла о взаимодействии с оперативной памятью, а время загрузки ячейки из основной оперативной памяти намного превышает штрафное пенальти конфликта кэш-линий, поэтому, мы, как помнится, пришли к выводу, что потоковые данные выравнивать бессмысленно.
Если же данные целиком умещаются в кэш-памяти первого (второго) уровня, то пагубное влияние кэш-конфликтов достигает весьма значительных величин, но… только на неразвернутых циклах. Воспользуемся несколько модернизированной программой Memory/aling.c чтобы изучить этот вопрос поподробнее. Уменьшим размер блока до 8-16 Кб и запустим программу…
На неразвернутом цикле чтения (см. рис. graph 0x007) даже P-III показал всего лишь 7% падение производительности, чего и следовало ожидать, т.к. во время кэш-конфликта процессор не простаивает, а обрабатывает команды, составляющие тело цикла, практически полностью маскируя задержку.
А вот неразвернутый цикл записи… ой-ой-ой! Четырехкратное отставание по скорости это вам не тигру хвост оторвать. Чем же вызвано это…. ну там мягко скажем безобразие? А вот чем: хитрый компилятор Microsoft Visual C++ заменил цикл записи всего одной машинной командой REP STOSD, чем к минимуму свел накладные расходы на организацию цикла. Кроме того, поскольку длина буферов записи равна длине кэш-линейке, совмещение начального адреса записи с адресом начала кэш линейки, обеспечивает эффективную трансляцию адресов, позволяя выгружать весь 32-байтный буфер всего за один такт.
На фоне этого 100% результат AMD Athlon выглядит весьма сильно, правда, при развороте циклов он все же начинает сдавать, отставая от выровненного варианта на 24% при чтении и на 48% при записи данных.Впрочем, P-III выглядит ее слабее: +74% и +133% соответственно.
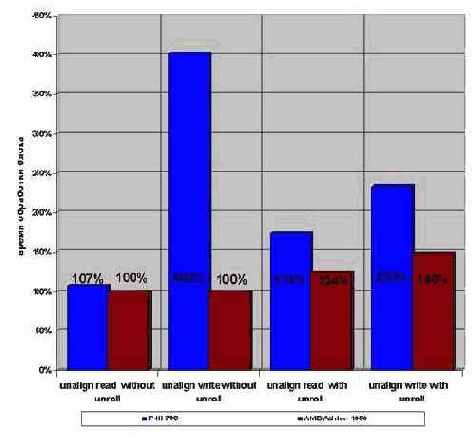
Рисунок 26 graph 0x07 Влияние выравнивания данных на производительность
Задержка окажется еще большей, если запрошенные данные в L1-кэше отсутствуют – тогда потребуется считать из L2-кэша обе кэш-линии, на что в среднем уйдет от 8 до 12 тактов. Если же и в L2-кэше этих злощасных данных нет, - придется ожидать загрузки аж 512 бит (64 байт) из основной памяти. А это в лучшем случае полсотни тактов процессора!
Впрочем,