Сравнительная характеристика основных типов памяти
С точки зрения пользователя PC главная характеристика памяти это – скорость
или, выражаясь другими словами, ее быстродействие. Казалось бы, что может быть проще, чем измерять быстродействие? Достаточно подсчитать количество информации, выдаваемой памятью в единицу времени (скажем, мегабайт в секунду), и… ничего не получится! Ведь, как мы уже знаем, время доступа к памяти непостоянно и, в зависимости от характера обращений, варьируется в очень широких пределах. Наибольшая скорость достигается при последовательном чтении, а наименьшая – при чтении в разброс. Но и это еще не все! Современные модули памяти имеют несколько независимых банков и потому позволяют обрабатывать несколько запросов параллельно.
Если запросы следуют друг за другом непрерывным потоком, непрерывно генерируются и ответы. Несмотря на то, что задержка между поступлением запроса и выдачей соответствующего ему ответа может быть весьма велика, в данном случае это не играет никакой роли, поскольку латентность (т.е. величина данной задержки) полностью маскируется конвейеризацией и производительность памяти определяется исключительно ее пропускной способностью. Можно провести следующую аналогию: пусть сборка одного отдельного взятого Мерседеса занимает ну, скажем, целый месяц. Однако если множество машин собирается параллельно, завод может выдавать хоть по сотне Мерседесов в день и его "пропускная способность" в большей степени определяется именно количеством сборочных линий, а не временем сборки каждой машины.
В настоящее время практически все производители оперативной памяти маркируют свою продукцию именно в пропускной способности, но наблюдающийся в последнее время стремительный рост пропускной способности (см. рис. graph 30), адекватного увеличения производительности приложений, как это ни странно, не вызывает. Почему?
Основной камень преткновения – фундаментальная проблема зависимости по данным (см. "Оптимизация работы с памятью: устранение зависимости по данным"). Рассмотрим следующую ситуацию.
Пусть ячейка N1 хранит указатель на ячейку N 2, содержащую обрабатываемые данные. До тех пор, пока мы не получим содержимое ячейки N 1, мы не сможем послать запрос на чтение ячейки N 2, поскольку, еще не знаем ее адреса. Следовательно, производительность памяти в данном случае будет определяться не пропускной способностью, а латентностью. Причем, не латентностью микросхемы памяти, а латентностью всей подсистемы памяти – кэш-контроллером, системной шиной, набором системной логики… Латентность всего это хозяйства очень велика и составляет порядка 20 тактов системной шины, что многократно превышает полное время доступа к ячейке оперативной памяти. Таким образом, при обработке зависимых данных быстродействие памяти вообще не играет никакой роли – и SDRAM PC100, и RDRAM-800 покажут практически идентичный результат!
Причем, описываемый случай отнюдь не является надуманным, скорее наоборот – это типичная ситуация. Основные структуры данных (такие как деревья и списки) имеют ярко выраженную зависимость по данным, поскольку объединяют свои элементы именно посредством указателей, что "съедает" весь выигрыш от быстродействия микросхем памяти.
Таким образом, теоретическая пропускная способность памяти, заявленная производителями, совсем ничего не говорит о ее реальной производительности.
|
Тип памяти |
Рабочая частота, MHz |
Разрядность, бит |
Время доступа, нс. |
Время рабочего цикла, нс. |
Пропускная способность, Мбайт/c |
|
FPM |
25, 33 |
32 |
70, 60 |
40, 35 |
100, 132 |
|
EDO |
40, 50 |
32 |
60, 50 |
25, 20 |
160, 200 |
|
SDRAM |
66, 100, 133 |
64 |
40, 30 |
10, 7.5 |
528, 800, 1064 |
|
DDR |
100, 133 |
64 |
30, 22.5 |
5, 3.75 |
1600, 2100 |
|
RDRAM |
400, 600, 800 |
16 |
,,30 |
,,2.5 |
1600, 2400, 3200 |
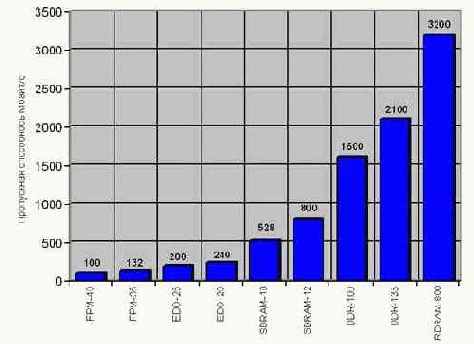
Рисунок graph 30 Максимально достижимая пропускная способность основных типов памяти