третий. Выравнивание данных
Тем не менее профилировка показывает, что количество горячих точек не только сократилось, но даже возросло на одну! Почему? Так дело в том, что алгоритм подсчета горячих точек учитывает не абсолютное, а относительное быстродействие различных частей программы по отношению друг к другу. И по мере удаления самых больших пиков, на диаграмме появится более мелка "рябь".
Несмотря на оптимизацию, функция CalculateCRC, по прежнему идет "впереди планеты всей", отхватывая более 50% всего времени исполнения программы. Но теперь самой горячей точной становится пара команд:
mov edi, DWORD PTR [eax+esi]
add edx, edi
Хм! Что же в них такого особенного? Ну да, тут налицо обращение к памяти (x += *(int *)((int)pswd + a)), но ведь тестируемый пароль по идее должен находится в кэше первого уровня, доступ к которому занимает один такт. Может быть, кто-то вытеснил эти данные из кэша? Или произошел какой-нибудь конфликт? Попробуй тут разберись! Можно бесконечно ломать голову, поскольку причина вовсе не в этом коде, а совсем в другой ветке программы…
Вот тут самое время прибегнуть к одному из мощнейших средств VTune – динамическому анализу, позволяющему не только определить куда уходят такты, но и выяснить причины этого. Причем, динамический анализ выполняется отнюдь не на "живом" процессоре, а… его программном эмуляторе. Это здорово экономит ваши финансы! Для оптимизации вовсе не обязательно приобретать всю линейку процессоров – от Intel 486 до Pentium-4, – достаточно приобрести один VTune, и можете запросто оптимизировать свои программы под Pentium-4, имея в наличии всего лишь Pentium-II или Pentium-III.
Перед началом динамического анализа, вам требуется указать какую именно часть программы вы хотите профилировать. В частности, можно анализировать как одну "горячую" точку функции Calculate CRC, так и всю функцию целиком. Поскольку, наша подопечная функция содержит множество "горячих" точек, выберем последний вариант.
Прокручивая экран вверх, переместим курсор в строку с меткой "Calculate CRC" (метки отображаются в второй слева колонке экрана). Если же такой строки не окажется, найдем на панели инструментов кнопку, с голубым треугольником, направленным вверх (Scroll to Previous Portal) и нажмем ее. Теперь установим точку входа (Dynamic Analyses Entry Pont) которая задается кнопкой с желтой стрелкой, направленной вправо. Аналогичным образом задается и точка выхода (Dynamic Analyses Exit Pont) – прокручивая экран вниз, добираемся до последней строки Calculate CRC (она состоит всего из одной команды – ret) и, пометив ее курсором, нажимаем кнопку с желтой стрелкой, направленной налево. Теперь – "Run\Dynamic Analysis Session". В появившимся диалоговом окне выбираем эмулируемую модель процессора (в нашем случае – P-III) на нажимаем "Start". Поехали!
Профилировщик вновь запустит программу и, погоняя ее минуту-другую, выдаст приблизительно следующее окно (см. рис. 0x004).
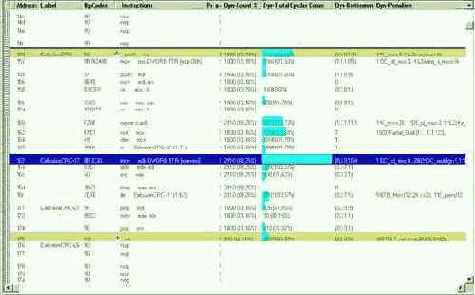
Рисунок 9 0х004 Динамический анализ программы не только определяет температуру каждой машинной инструкции, но и объясняет причины ее "нагрева"
Ага! Вот она наша горячая точка (на рисунке она отмечена курсором). Двойной щелчок мыши вызывает информационный диалог, подробно описывающий проблему :
Decoder Minimum Clocks = 0, ; // Минимальное время декодирования 0 тактов
Decoder Average Clocks = 0.7 ; // Среднее время декодирования 0.7 тактов
Decoder Maximum Clocks = 14 ; // Максимальное время декодирования 14 тактов
Retirement Minimum Clocks = 0, ; // Минимальное время завершения 0 тактов
Retirement Average Clocks = 6.9 ; // Среднее время завершения 6.9 тактов
Retirement Maximum Clocks = 104 ; // Максимальное время завершения 104 такта
Total Cycles = 20117 (35,88%) ; // Полное время исполнения 20.117 тактов (35,88%)
Micro-Ops for this instruction = 1 ; // Инструкция декодируется в одну микрооперацию
// Инструкция ждала (0, 0.1, 2) цикла пока ее операнды не были готовы
The instruction had to wait (0,0.1,2) cycles for it's sources to be ready
Warnings: 3*decode_slow:0 ; // Конфликтов декодеров – нет
Dynamic Penalty: DC_rd_miss
The operand of this load instruction was not in the data cache. The instruction stalls while the processor loads the specified address location from the L2 cache or main memory.
(Операнд этой инструкции отсутствовал в кэше данных. Инструкция ожидала пока процессор загрузит соответствующие данные из кэша второго уровня или основной памяти).
Occurrences = 1 ; // Случалось один раз
Dynamic Penalty: DC_misalign
The instruction stalls because it accessed data that was split across two data-cache lines.
(Инструкция простаивала, потому что она обращалась к данным "расщепленным" через две кэш-линии)
Occurrences = 2000 ; // Случалось 2000 раз
Dynamic Penalty: L2data_rd_miss
The operand of this load instruction was not in the L2 cache. The instruction stalls while the processor loads the specified address location from main memory.
(Операнд этой инструкции отсутствовал в кэше второго уровня. Инструкция ожидала пока процессор загрузит соответствующие данные из основной памяти).
Occurrences = 1 ; // Случалось один раз
Dynamic Penalty: No_BTB_info
The BTB does not contain information about this branch. The branch was predicted using the static branch prediction algorithm.
(BTB – Branch Target Buffer – буфер ветвлений не содержал информацию об этом ветвлении.
Ветка была предсказана статическим алгоритмов предсказаний).
Occurrences = 1 ; // Случалось один раз
Какая богатая кладезь информации! Оказывается, кэш тут действительно не причем (кэш-промах произошел всего один раз), а основной виновник – доступ к не выровненным данным, который имел место аж 2000 раз, – именно столько, сколько и прогонялась программа. Т.е. такое происшествие случалось на каждой итерации цикла – отсюда и тормоза.
Смотрим, – где в программе инициализируется указатель pswd? Ага, вот фрагмент кода из тела функции main (надеюсь, теперь вам понятно, почему статически анализ функции Calculate CRC был неспособен что-либо дать?):
pswd = (char *) malloc(512*1024);
pswd+=62;
Листинг 15 Выравнивание парольного буфера для предотвращения штрафных санкций со стороны процессора
Убираем строку "pswd += 62"
и перекомпилируем программу. Четыре с половиной миллиона паролей в секунду! Держи тигра за хвост!