десятый. Заключительный
Все оставшиеся 17 горячих точек представляют собой издержки обращения к кэш-памяти и… штрафные такты ожидания за неудачную с точки зрения процессора группировку команд. Ладно, оставим обращения к памяти в стороне, вернее отдадим эту задачу на откуп неутомимым читателям (задумайтесь: зачем вообще теперь генерировать пароли, если их контрольная сумма считается без обращения к ним?) и займемся оптимальным планированием потока команд.
Обратимся к другому мощному средству профилировщика VTune – автоматическому оптимизатору, по праву носящему гордое имя "Assembly Coach" (Ассемблерный Тренер, – не путайте его с Инструктором!). Выделим, удерживая левую клавишу мыши, все тело функции gen_pswd
и найдем на панели инструментов кнопку с "учителем" (почему-то ярко-красного цвета), держащим указку на перевес. Нажмем ее.
На выбор нам предоставляется три варианта оптимизации, выбираемые в ниспадающем боксе "Mode of Operation" – Автоматическая Оптимизация (Automatic Optimization), Пошаговая Оптимизация (Single Step Optimization) и Интерактивная Оптимизация (Interactive Optimization). Первые два режима представляют собой сплошное барахло, не представляющего особого интереса, а вот качество Интерактивной Оптимизации – выше всяких похвал. Итак, выбираем интерактивную оптимизацию и нажимаем кнопку "Next" расположенную чуть правее ниспадающего бокса.
Содержимое экрана тут же преобразится (см. рис 0х005): в левой панели показан исходный ассемблерный код, в правой – оптимизируемый код. В нижнем углу экрана по ходу оптимизации будут отображаться так называемые "assumption" (буквально – допущения), за разрешением которых оптимизатор будет обращаться к программисту. Сейчас в этом окне горит следующее допущение: "Offset: 0x55 & 0x72: Instructions Reference to Same Memory" (Инструкции со смещениями 0x55 и 0x72 обращаются к одной и той же области памяти). Смотрим: что за инструкции расположены по таким смещениям. Ага:
1:55 mov ebp, DWORD PTR [esp+018h]
1:72 mov DWORD PTR [esp+010h], ecx
Несмотря на кажущееся различие в операндах, на самом деле они адресуют одну и ту же переменную, т.к. между ними расположены две машинные команды PUSH, уменьшающие значение регистра ESP на 8. Таким образом, это предположение верно и мы подтверждаем его нажатием "Apply".
Теперь обратим внимание на инструкции, залитые красным цветом и отмеченные красным огоньком светофора слева. Это отвратительно спланированные инструкции, обложенные штрафными тактами процессора.
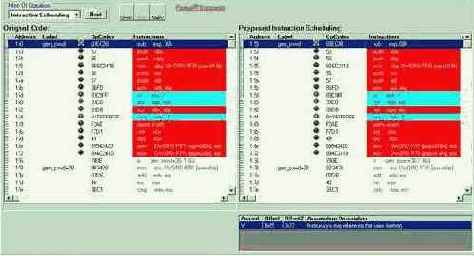
Рисунок 10 0x005 Использование Ассемблерного Тренера для оптимизации планирования машинных команд
Давайте щелкнем по самому нижнему "светофору" и посмотрим, как VTune перегруппирует наши команды… Ну вот, совсем другое дело! Теперь все инструкции залиты пастельным желтым цветом, что означает: никаких конфликтов и штрафных тактов – нет. Что в оптимизированном коде изменилось? Ну, во-первых, теперь команды PUSH (заталкивающие регистры в стек) отделены от команды, модифицирующей регистр указатель вершины стека, что уничтожает паразитную зависимость по данным (действительно, нельзя заталкивать свежие данные в стек пока не известно положение его вершины).
Во-вторых, арифметические команды теперь равномерно перемешаны с командами записи/чтения регистров, – поскольку вычислительное устройство (АЛУ – арифметически логическое устройство) у процессоров Pentium всего одно, то эта мера практически удваивает производительность.
В-третьих, процессоры Pentium содержат только один полноценный x86 декодер и потому заявленная скорость декодирования три инструкции за такт достигается только при строго определенном следовании инструкцией. Инструкции, декодируемые только полноценным x86-декодером, следует размещать в начале каждого триплета, заполняя "хвост" триплета командами, которые по зубам остальным двум декодерам. Как легко убедиться, компилятор MS VC генерирует весьма неоптимальный с точки зрения Pentium-процессора код и VTune перетасовывает его команды по своему.
sub esp, 08h sub esp, 08h
push ebx or ecx, -1
push ebp push ebx
mov ebp, DWORD PTR [esp+018h] push ebp
push esi mov ebp, DWORD PTR [esp+018h]
push edi xor eax, eax
mov edi, ebp push esi
or ecx, -1 push edi
xor eax, eax xor ebx, ebx
xor ebx, ebx mov edx, -1
mov edx, -1 mov edi, ebp
repne scasb repne scasb
not ecx mov DWORD PTR [esp+020h], edx
dec ecx not ecx
mov DWORD PTR [esp+020h], edx dec ecx
mov DWORD PTR [esp+010h], ecx mov DWORD PTR [esp+010h], ecx
Листинг 20 Ассемблерный код, оптимизированный компилятором Microsoft Visual C++ 6.0 в режиме максимальной оптимизации (слева) и его усовершенствованный вариант, переработанный VTune (справа).
Нажимаем еще раз "Next" и переходим к анализу следующего блока инструкций. Теперь VTune устраняет зависимость по данным, разделяя команды чтения и сложения регистра ESI командой увеличение регистра EAX
mov esi, DWORD PTR [eax+ebp] mov esi, DWORD PTR [eax+ebp]
add edx, esi inc eax
inc eax add edx, esi
cmp eax, ecx cmp eax, ecx
…и таким Макаром мы продолжаем до тех пор, пока весь код целиком не будет оптимизирован.
И тут возникает новая проблема. Как это ни прискорбно, но VTune не позволяет поместить оптимизированный код в исполняемый файл, видимо, полагая, что программист–ассемблерщик без труда перебьет его с клавиатуры и вручную. Но мы то с вами не ассемблерщики! (В смысле: среди нас с вами есть и не ассемблерщики).
И потом – куда прикажите перебивать код? Не резать же двоичный файл "в живую"? Конечно нет! Давайте поступим так (не самый лучший вариант, конечно, но ничего более умного мне в голову пока не пришло). Переместив курсор в панель оптимизированного кода в меню файл выберем пункт "печать". В окне "Field Selection" (выбор полей) снимем галочки со всего, кроме "Labels" (метки) и "Instructions" (инструкции) и зададим печать в файл или буфер обмена.
Тем временем, подготовим ассемблерный листинг нашей программы, задав в командной строке компилятора ключ "/FA" (в других компиляторах этот ключ, разумеется, может быть и иным). В результате мы станем обладателями файла pswd.asm, который даже можно откомпилировать ("ml /c /coff pswd.asm"), слинковать ("link /SUBSYSTEM:CONSLE pswd.obj LIBC.LIB") и запустить. Но что за черт! Мы получаем скорость всего ~65 миллионов паролей в секунду против 83 миллионов, которые получаются обычным путем. Оказывается, коварный MS VC просто не вставляет директивы выравнивания в ассемблерный текст! Это затрудняет оценку производительности качества оптимизации кода профилировщиков VTune. Ну да ладно, возьмем за основу данные 65 миллионов и посмотрим насколько VTune сможет улучшить этот результат.
Открываем файл, созданный профилировщиком и… еще одна проблема! Его синтаксис совершенно не совместим с синтаксисом популярных трансляторов ассемблера!
Label Instructions
gen_pswd sub esp, 08h
js gen_pswd+36 (1:86)
gen_pswd+28 mov esi, DWORD PTR [eax+ebp]
Листинг 21 Фрагмент ассемблерного файла, сгенерированного VTune
Во-первых, после меток не стоит знак двоеточия, во-вторых, в метках встречается запрещенный знак "плюс", в третьих, условные переходы содержат лишний адрес, заключенный в скобки на конце.
Словом нам предстоит много ручной работы, после которой "вычищенный" фрагмент программы будет выглядеть так:
Label Instructions
gen_pswd: sub esp, 08h
js gen_pswd+_36 (1:86)
gen_pswd+_28 mov esi, DWORD PTR [eax+ebp]
Листинг 22 Исправленный фрагмент сгенерированного VTune файла стал пригоден к трансляции ассемблером TASM или MASM
Остается заключить его в следующую "обвязку" и оттранслировать ассемблером TASM или MASM – это уже как вам по вкусу:
.386
.model FLAT
PUBLIC _gen_pswd
EXTERN _DeCrypt:PROC
EXTRN _printf:NEAR
EXTRN _malloc:NEAR
_DATA SEGMENT
my_string DB 'CRC %8X: try to decrypt: "%s"', 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
_gen_pswd PROC NEAS
// код функции gen_pswd
_gen_pswd ENDP
_TEXT ENDS
END
Листинг 23 "Обвязка" ассемблерного файла в которую необходимо поместить оптимизированный код функции _gen_pswd для его последующей трансляции
А в самой программе pswd.c функцию gen_pswd объявить как внешнюю. Это можно сделать например так:
extern int _gen_pswd(char *crypteddata,
char *pswd, int max_iter, int validCRC);
Листинг 24 Объявление внешней функции gen_pswd в Си-программе
Теперь можно собирать наш проект воедино:
ml /c /coff gen_pswd.asm
cl /Ox pswd.c /link gen_pswd.obj
Листинг 25 Финальная сборка проекта pswd
Прогон оптимизированной программы показывает, что она выдает ~78 миллионов паролей в секунду, что на ~20% чем было до оптимизации. Что ж! Профилировщик VTune весьма не хило оптимизирует код! Тем не менее, полученный результат все же не дотягивает до скорости, достигнутой на предыдущем шаге.Конечно, камень преткновения не в профилировщике, а в компиляторе, но разве от этого нам легче?
Впрочем, на оптимизацию собственных ассемблерных программ эта проблема никак не отражается.