Разворачивание циклов
Разворот циклов, – простой и весьма эффективный способ оптимизации. Конвейерные микропроцессоры крайне болезненно реагируют на ветвления, значительно уменьшая скорость выполнения программ (а цикл как раз и представляет собой одну из разновидностей ветвления). Образно говоря, процессор – это гонщик, мчащийся по трассе (программному коду) и сбрасывающий газ на каждом повороте (ветвлении). Чем меньше поворотов содержит трасса (и чем протяженнее участки беспрепятственной прямой),– тем меньше времени требуется на ее прохождение.
Техника разворачивания циклов в общем случае сводится к уменьшению количества итераций за счет дублирования тела цикла соответствующее число раз. Рассмотрим следующий цикл:
for(a = 0; a < 666; a++)
x+=p[a];
Листинг 2 Не оптимизированный исходный цикл
С точки зрения процессора этот цикл представляет собой сплошной ухаб, не содержащий ни одного мало-мальски протяженного прямого участка. Разворот цикла позволяет частично смягчить ситуацию. Чтобы уменьшить количество поворотов вдвое следует реорганизовать цикл так:
for(a = 0; a < 666; a+=2)
{// обратите внимание ^^^ с разверткой цикла
// мы соответственно увеличиваем и шаг
x+=p[a];
x+=p[a + 1]; // продублированное тело цикла
/* ^^^ корректируем значение счетчика цикла */
}
Листинг 3 Пример реализации двукратного разворота цикла
Разворот цикла в четыре раза будет еще эффективнее, но непосредственно этого не сделать, ведь количество итераций цикла не кратно четырем: 666 на 4 нацело не делится! Один из возможных путей решения: округлить количество итераций до величины кратной четырем (или, в более общем случае, – кратности разворота цикла), а оставшиеся итерации поместить за концом цикла.
Оптимизированный код может выглядеть, например, так:
for(a = 0; a < 664; a+=4)
{ // округляем ^^^ количество итераций до величины
// кратной четырем
x+=p[a]; // четырежды
x+=p[a + 1]; // дублируем
x+=p[a + 2]; // тело
x+=p[a + 3]; // цикла
}
x+=p[a]; // оставшиеся две итерации добавляем в конец
x+=p[a + 1]; // цикла
Листинг 4 Пример реализации четырехкратного разворота цикла в случае, когда количество итераций цикла не кратно четырем
Хорошо, а как быть, если количество итераций на стадии компиляции еще неизвестно? (То есть, количество итераций – переменная, а не константа). В этой ситуации разумнее всего прибегнуть к битовым операциям:
for(a = 0; a < (N & ~3); a += k)
{ // округляем ^^^ количество итераций до величины
// кратной степени разворота
x+=p[a];
x+=p[a + 1];
x+=p[a + 2];
x+=p[a + 3];
}
// оставшиеся итерации добавляем в конец цикла
for(a = (N & ~3)); a < N; a++)
x+=p[a];
Листинг 5 Пример реализации четырехкратного разворота цикла в случае заранее неизвестного количества итераций
Как нетрудно догадаться, выражение (N & ~3)) и осуществляет округление количества итераций до величины кратной четырем. А почему, собственно, четырем? Как вообще зависит скорость выполнения цикла от глубины его развертки? Что ж, давайте поставим эксперимент! Несколько забегая вперед отметим, что эффективность оптимизации зависит не только от глубины развертки цикла, но и рода обработки данных. Поэтому, циклы, читающие память, и циклы, записывающие память, должны тестироваться отдельно. Вот с чтения памяти мы, пожалуй, и начнем…
/* -----------------------------------------------------------------------
не оптимизированный вариант
(чтение)
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a += sizeof(int))
x += *(int *)((int)p + a);
/* -----------------------------------------------------------------------
разворот на четыре итерации
(чтение)
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a += 4*sizeof(int))
{
x += *(int *)((int)p + a );
x += *(int *)((int)p + a + 1*sizeof(int));
x += *(int *)((int)p + a + 2*sizeof(int));
x += *(int *)((int)p + a + 3*sizeof(int));
}
Листинг 6 [Memory/unroll.read.c] Фрагмент программы, исследующий влияние глубины развертки цикла, читающего память, на время его выполнения
Что ж, результаты тестирования нас не разочаровали! Оказывается, глубокая развертка цикла сокращает время его выполнения более чем в два раза. Впрочем, здесь главное – не переборщить! (Скупой, как хорошо известно, платит дважды). Чрезмерная глубина развертки ведет к катастрофическому увеличению размеров цикла и совершенно не оправдывает привносимый ей выигрыш. Шестидесяти четырех кратное дублирование тела цикла смотрится довольно таки жутковато. Хуже того, – такой монстр может просто не влезть в кэш, что вызовет просто обвальное падение производительности!
Целесообразнее всего, как следует из диаграммы graph 28, разворачивать цикл в восемь или шестнадцать раз. Дальнейшее увеличение степени развертки практически не добавляет производительности.
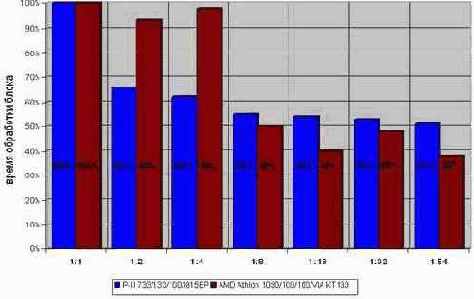
Рисунок 16 graph 28 Эффективность разворачивания циклов, читающих память. Видно, что время выполнения цикла резко уменьшается с его глубиной
С записью же картина совсем другая (см. рис. graph 29). /* Поскольку, тестовая программа мало чем отличается от предыдущей ради экономии места она опускается. */ На P?III/I815EP время выполнения цикла, записывающего память, вообще не зависит от глубины развертки. Ну, практически не зависит. Развернутый цикл выполняется на ~2% медленнее за счет потери компактности кода. Впрочем, этой величиной можно и пренебречь. Для увеличения эффективности выполнения программы под процессором Athlon следует развернуть записывающий цикл в шестнадцать раз. Это практически на четверть повысит его быстродействие!
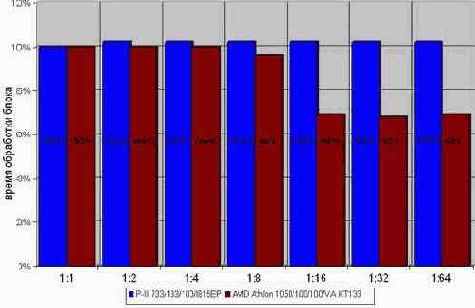
Рисунок 17 graph 29 Эффективность разворачивания циклов, записывающих память. Время выполнения цикла практически не зависит от глубины развертки и лишь на AMD Athlon шестнадцати кратная развертка несколько увеличивает его производительность
Что же касается смешанных циклов, обращающихся к памяти и на запись, и на чтение одновременно, – их так же рекомендуется разворачивать в восемь–шестнадцать раз. (см. так же "Группировка операций чтения с операциями записи").
Разворот циклов средствами макроассемблера. В заключении отметим одно печальное обстоятельство. Препроцессор языка Си не поддерживает циклических макросов и потому не позволяет реализовывать эффективную развертку циклов. Программист вынужден самостоятельно проделывать утомительную и чреватую ошибками работу по многократному дублированию тела цикла, не забывая к тому же о постоянной коррекции счетчика.
"Астматики" находятся гораздо в лучшем положении. Развитые макросредства ассемблеров MASM и TASM позволяют переложить всю рутинную работу на компилятор, и программисту ничего не стоит написать макрос разворачивающий цикл какое угодно количество раз. Это необычайно облегчает отладку и оптимизацию программы!
Одна из таких программ и приведена ниже в качестве наглядной иллюстрации. Согласитесь, элегантно решить эту (отнюдь не надуманную!) задачу средствами ANSI Cи/Си++ физически невозможно!
; /* -------------------------------------
; *
; * макрос, дублирующий свое тело N раз
; *
;
-------------------------------------- */
READ_BUFF MACRO N
MYN = N
MYA = 0
; // цикл дублирования своего тела
WHILE MYA NE MYN
; // тело цикла
; // макропроцессор продублирует его заданное число раз
MOV EDX, [EBX + 32 * MYA]
MYA = MYA + 1
ENDM
ENDM
UNROLL_POWER EQU 8 ; // глубина разворота цикла
Loop:
READ_BUFF UNROLL_POWER
; // ^^^^^^^^^^^^ обратите внимание, глубина разворота
; // задается препроцессорной константой!
; // никакой ручной работы!
ADD EAX, EDX
ADD EBX, 4 * UNROLL_POWER
; // коррекция ^^^^^^^^^^^^^^ количества итераций
DEC ECX
JNZ Loop
Листинг 7 Пример разворачивания цикла средствами макроассемблера. Макрос READ_BUFF позволяет разворачивать цикл произвольное количество раз
Разворот цикла средствами препроцессора Си. Хотя автоматически развернуть цикл директивами препроцессора ANSI Cи/Си++ невозможно, пути изгнания рутины из жизни программиста все-таки существуют! Стоит только подумать…
Одна из идей состоит в отказе от модификации счетчика цикла внутри заголовка цикла и выполнении этой операции внутри макроса "продразверстки". В результате, необходимость ручной коррекции счетчика отпадает и все копии тела цикла становятся идентичны друг другу. А раз так, – почему бы их не засунуть в препроцессорный макрос?
Это можно сделать, например, так:
#define BODY x+=p[a++]; // тело цикла
for(a=0; a < BLOCK_SIZE;)
{
// разворот цикла в 8 раз
BODY; BODY; BODY; BODY;
BODY; BODY; BODY; BODY;
}
Листинг 8 Пример разворачивания цикла средствами препроцессора языка Си. Это лучшее, что язык Си в состоянии нам предложить