Практическое использование предвыборки
Если вычислительный алгоритм позволяет с той или иной вероятностью предсказать адрес следующей обрабатываемой ячейки – это хороший кандидат на оптимизацию, причем выигрыш от использования предвыборки будет тем значительнее, чем точнее определяется адрес следующей обрабатываемой ячейки. В первую очередь это относится к циклам с постоянным шагом, геометрическим преобразованиям в 2D/3D графике, операциям сортировки, копирования и инициализация памяти, строковым операциям и т.д. В меньшей степени поддается оптимизации обработка списков и двоичных деревьев. Поскольку, порядок размещения их элементов заранее не известен и определяется исключительно в процессе прохода по списку (дереву), гарантированно определить адрес следующего обрабатываемого элемента в общем случае невозможно. Однако достаточно часто его удается угадать. Например, можно предположить, что начало очередного элемента находится непосредственно за концом текущего. Если список (двоичное дерево) не очень сильно фрагментирован, процент попаданий значительно превосходит количество промахов и предвыборка дает положительный эффект.
Рассмотрим следующий пример:
#define STEP_SIZE L1_CACHE_LINE_SIZE
for(a=0;a<BLOCK_SIZE;a+=STEP_SIZE)
{
// Делаем некоторые вычисления (какие - не важно)
_jn(c, b);
// Считываем очередную ячейку
b+=p[c];
}
Листинг 20 Кандидат на оптимизацию с использованием предвыборки
Если обрабатываемый блок отсутствует в кэше первого и второго уровней, а шаг цикла равен или превышает размер кэш-линейки, то каждое обращение к памяти будет вызывать значительную задержку – порядка 10-12 тактов системной шины, требующихся на передачу запрашиваемых ячеек из медленной оперативной памяти в быстрый кэш. На P-III 733 это составит более полусотни тактов процессора! В результате – время выполнения данного примера в большей степени зависит от быстродействия подсистемы памяти, и в меньшей – от тактовой частоты процессора.
Однако поскольку адрес очередной обрабатываемой ячейки известен заранее, данные можно загружать в кэш параллельно с выполнением вычислений.
Пример, оптимизированный под P-III, в первом приближении будет выглядеть приблизительно так:
#define STEP_SIZE L1_CACHE_LINE_SIZE
for(a=0;a<BLOCK_SIZE;a+=STEP_SIZE)
{
// Даем команду на загрузку следующей 32-байтной строки
// в L1-кэш. Загрузка будет осуществляться параллельно
// с выполнением функции _jn.
// Когда же соответствующая ячейка будет затребована,
// она уже окажется в L1-кэше, откуда процессор сможет
// извлечь ее безо всяких задержек.
_prefetchnta(p+c+STEP_SIZE);
// ^^^^^^^^ обратите внимание: в кэш
// загружается ячейка, обрабатываемая не в текущей, а
// следующей итерации цикла. Дело в том, что за время
// выполнения функций _jn запрашиваемая кэш-линейка
// просто не успевает загрузится!
// (подробнее см. "Планирование дистанции предвыборки")
// Выполняем некоторые вычисления
_jn(c, b);
// Считываем очередную ячейку
// Во всех, кроме первой, итерациях цикла ячейка будет
// гарантированно находиться в кэше первого уровня,
// в результате время ее чтения сократится до 1 такта CPU
b+=p[c];
}
Листинг 21 Оптимизированный вариант с использованием предвыборки [P-III]
На P-III 733/133/100 оптимизированный вариант выполняется быстрее на целых 64%, а на AMD Athlon 1050/100/100 – на ~60%, т.е. предвыборка увеличивает производительность более чем в два раза! (см. рис. 0х014) И это притом, что в цикле выполняется лишь одно обращение к памяти за каждую итерацию. А чем больше происходит обращений к памяти – тем больший выигрыш дает оптимизация!
Максимальный прирост производительности достигается в тех случаях когда: а) предвыборка данных осуществляется в кэш иерархию, соответствующую их назначению; б) запрашиваемые данные загружаются аккурат к моменту обращения; в) осуществляется предвыборка только тех данных, которым она действительно требуется (хотя prefetchx
– не блокируемая инструкция, и достаточно интеллектуальная для того, чтобы не загружать данные, уже находящиеся в кэше, ее обработка достается "не бесплатно" и лишние вызовы снижают производительность).
На P-4 данный пример в оптимизации вообще не нуждается, – процессор и сам, определив последовательность обращений к данным, осуществит их упреждающую загрузку самостоятельно. Инструкция программной предвыборки будет лишним балластом, лишь снижающим производительность системы (впрочем, не намного).
Для переноса примера 21 на K6 (VIA C3) достаточно лишь заменить инструкцию prefetchnta
на ее ближайший аналог – prefetch. А вот с переносом на Athlon дела обстоят намного сложнее. Попав на него, приведенный выше пример оптимизации покажет далеко не лучший результат: во-первых, предвыборка данных просто не успеет осуществиться за время выполнения функции _jn (ведь Athlon намного быстрее K6!) и процессор будет вынужден какое-то время простаивать, ожидая заполнения 64-байтной линейки кэша второго уровня. Во-вторых, вследствие того, что кэш-линейки на Athlon вдвое длиннее, чем на K6 (VIA C3), каждый второй запрос на предвыборку становятся бесполезным балластом, впустую отъедающим процессорное время. Проблема, однако!
Но программисты – на то они и программисты, чтобы не искать легких путей. К тому же, все проблемы решаемы…
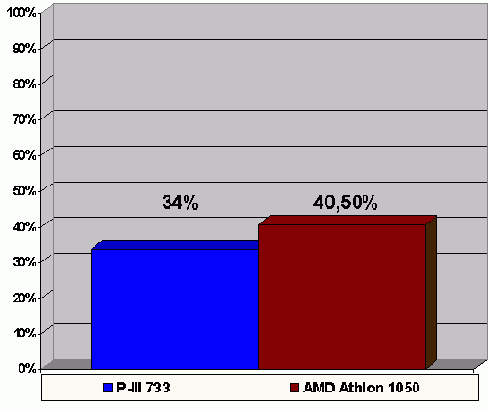
Рисунок 39 graph 0x014 Эффективность программной предвыборки в оптимизации примера 21