Понятие ассоциативности кэша
Проследим по шагам как работает кэш. Вот процессор обращается к ячейке памяти с адресом xyz. Кэш-контроллер, перехватив это обращение, первым делом пытается выяснить: присутствует ли запрошенные данные в кэш-памяти или нет? Вот тут-то и начинается самое интересное! Легко показать, что проверка наличия ячейки в кэш-памяти фактически сводится к поиску
соответствующего диапазона адресов в памяти тегов.
В зависимости от архитектуры кэш-контроллера просмотр всех тегов осуществляется либо параллельно, либо они последовательно перебираются один за другим. Параллельный поиск, конечно, чрезвычайно быстр, но и сложен в реализации (а потому – дорог). Последовательный же просмотр при большом количестве тегов крайне непроизводителен. Кстати, а сколько у нас тегов? Правильно – ровно столько, сколько и кэш-строк. Так, в частности, в 32килобайтном кэше насчитывается немногим более тысячи тегов.
Стоп! Сколько времени потребует просмотр тысячи тегов?! Даже если несколько тегов будут просматриваться за один такт, поиск нужной нам линейки растянется на сотни тактов, что "съест" весь выигрыш в производительности. Нет уж, какая динамическая память ни тормозная, а к ней обратится побыстрее будет, чем сканировать кэш…
Но ведь кэш все таки работает! Спрашивается: как? Оказывается (и это следовало ожидать), что последовательный поиск – не самый продвинутый алгоритм поиска. Существуют и более элегантные решения. Рассмотрим два наиболее популярные из них.
В кэше прямого отображения проблема поиска решается так: пусть каждая ячейка памяти соответствует не любой, а одной строго определенной строке кэша. В свою очередь, каждой строке кэша будет соответствовать не одна, а множество ячеек кэшируемой памяти, но опять-таки, не любых, а строго определенных.
Пусть наш кэш состоит из четырех строк, тогда (см. рис 0х10) первый пакет кэшируемой памяти связан с первой строкой кэша, второй – со второй, третий – с третьей, четвертый – с четвертой, а пятый – вновь с первой! Достаточно очевидно, что адреса ячеек кэшируемой памяти связаны с номерами кэш-строк следующим отношением: , где N – условный номер кэш-линейки, ADDR – адрес ячейки кэшируемой памяти; CACHE.LINE.SIZE – длина кэш-линейки в байтах; CACHE.SIZE – размер кэш-памяти в байтах; "—" – операция целочисленного деления.
Таким образом, чтобы узнать: присутствует ли искомая ячейка в кэш-памяти или нет, достаточно просмотреть всего один-единственный тег соответствующей кэш-линейки, для вычисления номера которого требуется совершить всего три арифметические операции (поскольку, длина кэш-линеек и размер кэш памяти всегда представляют собой степень двойки, операции деления и взятия остатка допускают эффективную и простую аппаратную реализацию). Необходимость просматривать все теги в этой схеме естественным образом отпадает.
Да, отпадает, но возникает другая проблема. Задумайтесь, что произойдет, если процессор попытается последовательно обратиться ко второй, шестой и десятой ячейкам кэшируемой памяти? Правильно – несмотря на то, что в кэше будет полно свободных строк, каждая очередная ячейка будет вытеснять предыдущую, т.к. все они жестко закреплены именно за второй строкой кэша. В результате кэш будет работать максимально неэффективно, полностью вхолостую (trashing).
Программист, заботящийся об оптимизации своих программ, должен организовать структуры данных так, чтобы исключить частое чтение ячеек памяти с адресами, кратными размеру кэша. Понятное дело – такое требование не всегда выполнимо и кэш прямого отображения обеспечивает далеко не лучшую производительность. Поэтому, в настоящее время он практически нигде не встречаются и полностью вытеснен наборно-ассоциативной сверхоперативной памятью.
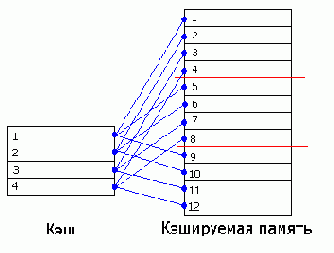
Рисунок 10 0x010 Устройство кэша прямого отображения
Наборно-ассоциативным кэш состоит из нескольких независимых банков,
каждый из которых представляет собой самостоятельный кэш прямого отображения. Взгляните на рисунок 0х012. Видите, каждая ячейка кэшируемой памяти может быть сохранена в любой из двух строк кэш-памяти. Допустим, процессор читает шестую и десятую ячейку кэшируемой памяти. Шестая ячейка идет во вторую строку первого банка, в десятая – во вторую строку следующего банка, т.к. первый уже занят.
Количество банков кэша и называют его ассоциативностью (way).Легко видеть, что с увеличением степени ассоциативности, эффективность кэша существенно возрастает (редкие исключения из этого правила мы рассмотрим позднее в главе "Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность").
В идеале, при наивысшей степени дробления, в каждом банке будет только одна линейка, и тогда любая ячейка кэшируемой памяти сможет быть сохранена в любой строке кэша. Такой кэш называют полностью ассоциативным кэшем или просто ассоциативным кэшем.
Ассоциативность кэш-памяти, используемой в современных персональных компьютеров колеблется от двух (2-way cache) до восьми (8-way cache), а чаще всего равна четырем (4-way cache).
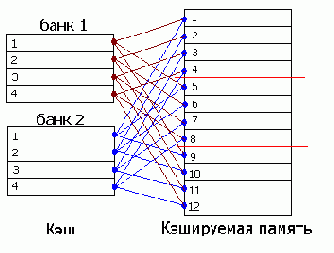
Рисунок 11 0х012 Устройство наборно-ассоциативного кэша