Планирование потоков данных
С проблемами, сопутствующими параллельной обработке нескольких блоков памяти (далее по тексту – потоков данных), мы уже столкнулись в предыдущем пункте. Здесь же этот вопрос будет рассмотрен более подробно. Итак, первое (и главное) правило – добиться, что бы потоки начинались с различных DRAM-банков (за TLB можно не беспокоиться, т.к. при параллельной обработке необходимые страницы уже будут там). Поскольку, большинство современных модулей памяти имеет четырех банковую организацию, очевидно, что работа с пятью и более потоками данных – нецелесообразна.
Однако это лишь вершина айсберга. Здесь, в зарослях тростника, притаилось немало тонкостей. Возьмем, например, руководство по чипсету VIAKT133. В нем черным по белому написано: "Supports maximum 16-bank interleave (i.e., 16 pages open simultaneously)… " – "Поддерживается чередование максимум 16-банков (т.е. 16 страниц могут быть открытыми одновременно)..." Означает ли это, что на чипсете VIA KT133 (и других, подобных ему, чипсетах) мы можем обрабатывать до 16 потоков данных? И да, и нет, причем скорее нет, чем да. Ключевое слово "максимум". Если воткнуть в системную плату всего один DIMM с четырех банковой организацией, то никакие конструкторские ухищрения не позволят чипсету удержать открытыми пять и более страниц DRAM-памяти. Поскольку микросхема памяти имеет всего лишь один сигнальный вывод RAS, то для открытия еще одной страницы в том же самом банке, этот сигнал придется дезактивировать, т.е. закрыть активную страницу.
Таким образом, крайне нежелательно обрабатывать более четырех потоков данных параллельно, в противном случае вы столкнетесь с проблемами производительности. Да, да, – хмыкнет читатель, – советовать что-либо не делать – проще всего. Гораздо сложнее найти решение как именно это делать! Положим, нам необходимо
обрабатывать более четырех потоков данных одновременно, причем, расплачиваться производительностью за постоянные открытия/закрытия DRAM-страниц мы категорически не хотим.
Тупик? Вылезаем, мы приехали? Вовсе нет!
Первое, что приходит на ум, – перейти на оперативную память типа RDRAM. В сочетании с чипсетом Intel 850 это обеспечит восемь реально открытых страниц, а это – восемь потоков данных! Удовлетворяет вас такое решение? В общем-то, да, но далеко не во всех случаях. RDRAM на сегодняшний день (точнее, момент написания этих строк – июнь 2002 года для справки) – не самый дешевый и распространенный тип памяти.
На самом деле, даже на обычной SDRAM памяти можно обрабатывать практически неограниченное
количество потоков данных, ничем не расплачиваясь взамен. Ведь никто не требует обрабатываемые именно физические
потоки. Вот и давайте, создав один физический поток, разобьем его на несколько логических (виртуальных) потоков или, другими словами говоря, используем interleave-трансляцию адресов. Тогда между адресами логических и физического потока будет установлено следующее соответствие:
p[N][a] == a*MAX_N + N /* 1 */
P[a] == a mod MAX_N /* 2 */
где:
p – массив указателей на адреса начала логических потоков,
P – указатель на адрес начала физического потока,
N – индекс логического потока,
а – индекс элемента логического потока N,
MAX_N – количество логических потоков,
"Живой" пример interleave–трансляции изображен на рис. 35. Смотрите, до оптимизации у нас было два обособленных блока памяти a) и b), каждый из которых хранил восемь ячеек памяти, обозначенных a0, a1…a7 и b0, b1…b7 соответственно. В оптимизированном варианте программы эти два блока объедены в один непрерывный блок, составленный из шестнадцати чередующихся ячеек блоков а и b, – a0, b0, a1, b1….a7, b7. Теперь, при параллельной обработке логических потоков a и b запрашиваемые данные сливаются в один физический поток, что: во-первых, позволяет избежать постоянного открытия/закрытия DRAM-страниц; во-вторых, гарантирует, что смежные ячейки потоков а и b не попадут на различные страницы одного и того же DRAM-банка, находящегося в момент обращения на регенерации.
И, в-третьих, облегчает работу системе аппаратной предвыборке (если таковая имеется), поскольку большинство таких систем оптимизированы всего под один поток (это легче реализовать, да и увеличение пакетного цикла обмена с памятью эффективно лишь при последовательном обращении к ней).
Причем, заметьте, все эти блага достаются практически даром и не слишком "утяжеляют" алгоритм. Правда, тут есть одна тонкость. Поскольку, переход от физического адреса потока к логическому, неизбежен без взятия остатка, то следует подумать: как избавиться от машинной команды DIV, выполняющей целочисленное деление. Дело в том, что деление – очень медленная операция, по времени приблизительно сопоставимая с закрытием одной DRAM-страницы. Если количество потоков соответствует степени двойки, то взятие остатка можно осуществить и быстрыми битовыми операциями. Другой путь – заменить взятие остатка умножением (см. ….).

Рисунок 30 0x35. Виртуализация потоков данных. Несколько исходных потоков (слева) сливаются в один физический
поток, сконструированный по принципу чередования адресов, что фактически равносильно его расщеплению на два логических
потока
Теперь давайте воочию убедимся насколько эффективной может быть оптимизация потоков при большом их числе. Для этого напишем следующую несложную программу и посмотрим на ее результат.
#define BLOCK_SIZE (2*M) // макс. объем виртуального потока
#define MAX_N_DST 16 // макс. кол-во виртуальных потоков данных
#define MAIL_ROOL(a) for(a = 2; a <= MAX_N_DST; a++)
/* ^^^^^^^ начинаем с двух виртуальных потоков */
int a, b, r, x=0;
int *p, *px[MAX_N_DST];
// шапка
printf("N DATA STREAM"); MAIL_ROOL(a) printf("\t%d",a);printf("\n");
/* -----------------------------------------------------------------------
*
* обработка потоков классическим (не оптимизированным) способом
*
------------------------------------------------------------------------ */
// выделяем память всем потокам
for (a = 0; a < MAX_N_DST; a++) px[a] = (int *) _malloc32(BLOCK_SIZE);
printf("CLASSIC");
MAIL_ROOL(r)
{
A_BEGIN(0) /* начало замера времени выполнения */
for(a = 0; a < BLOCK_SIZE; a += sizeof(int))
for(b = 0; b < r; b++)
x += *(int *)((int)px[b] + a );
// перебор всех потоков один за другим
// причем, как легко убедиться, ячейки
// всех потоков находятся в различных
// страницах DRAM, поэтому при обработке
// более четырех потоков, DRAM страницы
// будут постоянно закрываться/открываться
// снижая тем самым производительность
// ВНИМАНИЕ! в данном случае циклы a и b
// в принципе, возможно обменять местами,
// увеличив тем самым производительность,
// но мы же договорились обрабатывать
// потоки _параллельно_
A_END(0) /* конец замера времени выполнения */
printf("\t%d",Ax_GET(0)); // вывод времени обработки потока
} printf("\n"); /* end for */
/* -----------------------------------------------------------------------
*
* оптимизированная обработка виртуальных потоков
*
------------------------------------------------------------------------ */
// выделяем память физическому потоку
p = (int*) _malloc32(BLOCK_SIZE*MAX_N_DST);
printf("OPTIMIZED");
MAIL_ROOL(r)
{
A_BEGIN(1) /* начало замера времени выполнения */
for(a = 0; a < BLOCK_SIZE * r; a += (sizeof(int)*r))
// что изменилось? Смотрите, ^^^ - шаг приращения ^^^
// теперь равен кол-ву виртуальных потоков
for(b = 0; b < r; b++)
x += *(int *)((int)p + a + b*sizeof(int));
// теперь ячейки всех потоков расположены _рядом_
// поэтому, время их обработки - минимально
A_END(1) /* конец замера времени выполнения */
printf("\t%d",Ax_GET(1)); // вывод времени обработки потока
} printf("\n"); /* end for */
Листинг 20 [Memory/stream.virtual.c] Фрагмент программы, демонстрирующий эффективность виртуализации потоков в зависимости от их числа
Ого! Нет, конечно, мы догадывались, что оптимизирующий вариант обгонит классический, но кто же мог представить: насколько
он его обгонит! (см. рис. 13, 14). Вообще-то, на P-III 733/133/100/I815EP/2x4 вплоть до четырех потоков (максимально возможного количества одновременно открытых DRAM-страниц), оптимизированный вариант заметно отставал от не оптимизированного. Но уже на пяти потоках оба варианта сравнялись в скорости, а дальше… дальше с добавлением каждого нового потока время работы не оптимизированного варианта стало стремительно взлетать вверх. А у оптимизированного, напротив, – росло практически линейно (небольшие осцилляции объясняются особенностями кэш-подсистемы, о которых мы поговорим чуть позже см. "Кэш"). Так, уже на шестнадцати потоках (вполне реальная величина для типичных вычислительных задач), оптимизация дала более чем трехкратный выигрыш в скорости! И все это – повторяюсь, – без значительных изменений базового алгоритма. Оптимизацию потоков необязательно закладывать на этапе проектирования программы, – это можно сделать в любое удобное для разработчика время. К тому же, это далеко не предел производительности! Быстродействие программы можно значительно увеличить, если использовать параллельную обработку данных (см. "Параллельная обработка данных").
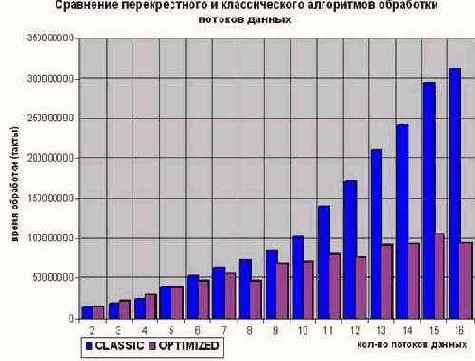
Рисунок 31 graph 13 Демонстрация эффективности виртуализации потоков данных на системе P-III 733/133/100/I815EP/2x4. Уже на 16 потоках оптимизация дает более чем трехкратный выигрыш
А вот и тесты системы AMD Athlon 1050/100/100/VIA KT133/4x4 (см. рис. graph 14). Забавно, но в данном случае оптимизированный вариант значительно обогнал не оптимизированный во всех случаях, даже при обработке всего двух потоков. Как же такое могло произойти? Помниться, документация обещала аж 16 одновременно открытых страниц, а на практике "сваливалась" всего лишь на двух. Верно, было нам такое обещано, но ведь в то же самое время утверждалось, что: "Four cache lines (32 quad words) of CPU to DRAM read prefetch buffers" – "Буфер предварительной выборки из DRAM, размером в четыре кэш-линии (32 четверых слова) центрального процессора [256 байт – КК]". Для уменьшения латентности инженеры из VIA решились на весьма ответственный шаг – осуществление упреждающего чтения из оперативной памяти. Алгоритм предвыборки должен уметь распознавать регулярные шаблоны обращения к данным и на их основе с высокой вероятностью предсказывать, к каким именно ячейкам произойдет следующее обращение. В противном случае от предвыборки будут одни убытки, – ведь в момент чтения оперативная память недоступна и вместо уменьшения латентности мы многократно увеличим ее!
К сожалению, документация вообще ничего не говорит о сценарии предвыборки, но ведь никто не запрещает нам догадываться, правда? Судя по всему, алгоритм упреждающего чтения в KT133 даже и не пытается распознать стратегию обращения к памяти, а просто загружает последующие 32 четверных слова при обращении ко всякой ячейке. Как следствие, – при работе с несколькими потоками данных содержимое буфера предвыборки будет вытесняться прежде, чем к нему произойдет реальное обращение и… "упрежденные" данные окажутся "упреждены" вхолостую. Отсюда и снижение производительности.
Поэтому, на чипсете VIA KT133 ( и подобных ему) крайне не рекомендуется работать более чем с одним физическом потоком данных. Причем, выигрыш в оптимизации даже превосходит систему на базе P-III/I815, – уже при 10 потоках наблюдается более чем пятикратный выигрыш! Не правда ли, VIA KT133 – хороший чипсет?

Рисунок 32 graph 14 Демонстрация эффективности виртуализации потоков данных на системе P-III/I815EP/2x4 AMD Athlon/VIA KT133/4x4
Особые случаи виртуализации потоков
Однако на этом сюрпризы не заканчиваются. Все что мы видим – верхушка айсберга. А если копнуть в глубь? Вот, например, как вы думаете: на каком минимальном расстоянии потоки данных могут располагаться друг от друга? Здравый смысл подсказывает: чем ближе, – тем лучше. А вот как бы не так! Особенности буферизации некоторых чипсетов (попросту говоря: криво реализованный механизм буферизации и/или неинтеллектуальной предвыборки) способен вызывать значительное снижение производительности, если происходит попеременное обращение к "близким" (с точки зрения чипсета) ячейкам памяти. Рассмотрим следующий пример:
for(a=0; a<BLOCK_SIZE; a+=STEP_FACTOR)
{
x += *(int *)((int)p + a );
y += *(int *)((int)p + a + DELTA_SIZE + STEP_FACTOR/2 );
}
Листинг 21 Пример неэффективного кода, не учитывающего особенности буферизации некоторых чипсетов
На системе Intel P-III 733/133/100/I815EP/2*4 время обработки блока практически не зависит от величины расстояния между потоками (DELTA_SIZE), естественно, если при этом не происходит постоянного попадания в один и тот же банк, но эту проблему мы уже обсудили (см. "Стратегия распределения данных по DRAM-банкам"). Казалось бы, какие тут могут быть сюрпризы? А вот взгляните на верхнюю кривую графика graph 12, иллюстрирующую поведение системы AMD Athlon 1050/100/100/VIA KT133/4 х 4. Оказывается, параллельная обработка данных, расположенных на расстоянии менее 512 байт друг от друга крайне невыгодна и несет чуть ли не двукратные издержки быстродействия.
Ох, уж эта система предвыборки в чипсете KT133! Конечно, можно просто заявить: "Используйте Intel (Intel – это рулез) и у вас не будет никаких проблем", но разработчик, заботящийся о своих клиентах, не должен ограничивать свободу выбора поставщика. Нравится кому-то VIA? – Да ради Бога! – Мы просто сместим начало каждого логического потока на 512 байт относительно предыдущего! Если количество требуемых потоков невелико, то с потерей нескольких килобайт можно и смириться, в противном случае возникнут попадания в регенерируемые банки и, – как следствие, – упадает производительность. Есть ли выход? Увы, общих решений нет… Правда, можно усложнить механизм трансляции адресов, расположив потоки приблизительно следующим образом: p0, 512 + p1, p2, 512 + p3…. тогда, при условии что потоки обрабатываются в строгой очередности, каждое обращение будет осуществляться без накладных расходов. Но что произойдет, если придется попеременно обращаться к данным потоков p1 и p3? Правильно – тормоза. Чтобы их избежать вам придется "заточить" механизм трансляции адресов потоков под алгоритм их обработки или… или вообще отказаться от оптимизации под VIA.
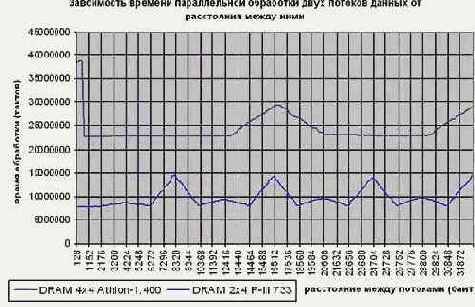
Рисунок 33 graph 12 Демонстрация особенностей механизма буферизации на чипсете VIA KT133. Смотрите, при узком "зазоре" между виртуальными потоками время их обработке чудовищно возрастает
Хорошо, с минимальным расстоянием мы разобрались. А существует ли максимально
разумное расстояние между потоками? Да, существует. И равно оно, как не трудно догадаться, – (N?1)*c /* на самом деле – даже (N?2)*c при хаотичной обработке блоков, но грамотным планированием потоков этой проблемы легко избежать */ Отсюда следует, что в один физический поток можно вместить не более чем: (N?1)*c/sizeof(element) логических потоков, где sizeof(element) – размер элементов потока. Так, для массивов, состоящих из элементов типа _int32, максимально разумное количество логических потоков равно: (4?1)*2048/4 == 1.536.
Не правда ли, это число более чем достаточно для всех – мыслимых и не мыслимых – задач?
Однако при этом максимально разумное количество физических потоков равно… одному. Ведь все DRAM-банки уже задействованы и при обращении ко второму физическому потоку никто не гарантирует, что мы не попадаем в регенерирующийся банк. Впрочем, тут все зависит от алгоритма работы с потоками, – вполне возможно добиться согласованной работы и четырех физических потоков, каждый из которых содержит по полторы тысячи логических. Но, постойте, сколько же это всего потоков получается? Шесть тысяч сто сорок четыре?! Трудно представить себе задачу, реально нуждающуюся в таком количестве потоков. Даже если это вычислительный кластер какой… Хотя, автору доводилось сталкиваться и с большим количеством параллельно обрабатываемых блоков данных – в системе, моделирующей движения звезд в галактиках, и пытающейся тем самым поближе подобраться к загадочной "темной материи", но это уже тема другого разговора… На персональных компьютерах пока подобные процессы не моделируют.