Параллельная обработка данных
Итак, обработка независимых данных выполняется намного быстрее, но насколько быстро она выполняется? Увы, если от относительных величин перейти к абсолютным цифрам,– весь восторг мгновенно улетучится и наступит глубокое уныние.
Наивысшая пропускная способность, достигаемая при линейном чтении независимых данных, составляет не более чем 40%-50% от завяленной пропускной способности данного типа памяти. И это притом, что подсистема памяти для линейного доступа как раз и оптимизирована, и хаотичное чтение ячеек происходит, по меньшей мере, на порядок медленнее. А что может быть быстрее линейного доступа? (Аналогичный вопрос: что может быть короче, чем путь по прямой). Вот с поиска ответов на такие вопросы и начинается проникновение в истинную сущность предмета обсуждения.
В обработке независимых данных есть одна тонкость. Попытка одновременного чтения двух смежных ячеек в подавляющем большинстве случаев инициирует один, а не два запроса к подсистеме памяти. Это не покажется удивительным, если вспомнить, что минимальной порцией обмена с памятью является не отнюдь не байт, а целый пакет, длина которого в зависимости от типа процессора варьируется от 32- до 128 байт.
Таким образом, линейное чтение независимых данных еще не обеспечивает их параллельной обработки (обстоятельство, о котором популярные руководства по оптимизации склонны умалчивать). Вернемся к нашей программе (см. листинг [Memory/dependence.c]). Вот процессору потребовалось узнать содержимое ячейки *(int *) ((int) p1 + a). Он формирует запрос и направляет его чипсету, а сам тем временем приступает к обработке следующей команды – x += *(int *)((int)p1 + a + 4). "Ага", – думает процессор, – зависимости по данным нет и это хорошо! Но, с другой стороны… эта ячейка и без того возвратится с предыдущим запрошенным блоком, и посылать еще один запрос нет необходимости (чипсет, сколько его ни подгоняй, он быстрее работать не будет). Что ж, придется отложить выполнение данной команды до лучших времен.
Так, что там у нас дальше? Следующая команда – x += *(int *)((int)p1 + a + 8)
тоже отправляется на "консервацию", поскольку пытается прочесть ячейку из уже запрошенного блока. В общем, до тех пор, пока чипсет не обработает вверенный ему запрос, процессор (при линейном чтении данных!) ничего не делает, а только "складирует". Затем, по мере готовности операндов, команды "размораживаются" и процессор завершает их выполнение.
…наконец процессору встречается команда, обращающаяся к ячейке, следующей за концом последнего запрошенного блока. "Эх", – вздыхает процессор, – "если бы она мне встретилась раньше, – я бы смог отправить чипсету сразу два запроса!".
Более эффективный алгоритм обработки данных выглядит так: в первом проходе цикла память читается с шагом 32 байта (или 64/128 байт, если программа оптимизируется исключительно под Athlon/P-4), что заставляет процессор генерировать запросы чипсету при каждом обращении к памяти. В результате, на шине постоянно присутствуют несколько перекрывающихся запросов/ответов, обрабатывающихся параллельно (ну, почти параллельно). Во втором проходе цикла считываются все остальные ячейки, адреса которых не кратны 32 байтам. Поскольку, на момент завершения первого прохода они уже находятся в кэше, обращение к ним не вызовет больших задержек (см. рис 39).
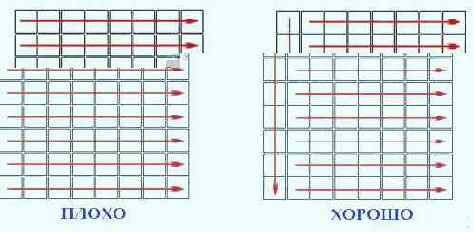
Рисунок 19 39. По возможности избегайте линейного чтения ячеек памяти. Лучше в первом проходе цикла читать ячейки с шагом, кратным размеру пакетного цикла обмена, а оставшиеся ячейки обрабатывать как обычно
Рассмотрим усовершенствованный вариант программы параллельного чтения независимых данных:
/* -----------------------------------------------------------------------
*
* измерение пропускной способности при параллельном чтении данных
*
----------------------------------------------------------------------- */
#define
BLOCK_SIZE (32*M) // размер обрабатываемого блока
#define
STEP_SIZE L1_CACHE_SIZE // размер обрабатываемого подблока
for (b=0; b < BLOCK_SIZE; b += STEP_SIZE)
{
// первый проход цикла, в котором осуществляется
// параллельная загрузка данных
for (a = b; a < (b + STEP_SIZE); a += 128)
{
// загружаем первую ячейку;
// поскольку ее пока нет в кэше,
// процессор отправляет чипсету
// запрос на ее чтение
x += *(int *)((int)p + a + 0);
// загружаем следующую ячейку
// поскольку зависимости по данным нет,
// процессор может выполнять эту команду,
// не дожидаясь результатов предыдущей
// но, поскольку процессор видит, что
// данная ячейка не возвратиться с
// только что запрошенным блоком,
// он направляет еще чипсету еще один запрос
// не дожидаясь завершения предыдущего
x += *(int *)((int)p + a + 32);
// аналогично, - теперь на шине уже три запроса!
x += *(int *)((int)p + a + 64);
// на шину отправляется четвертый запрос,
// причем, первый запрос возможно еще и
// не завершен
x += *(int *)((int)p + a + 96);
}
for (a = b; a < (b + STEP_SIZE); a += 32)
{
// следующую ячейку читать не надо
// т.к. она уже прочитана в первом цикле
// x += *(int *)((int)p + a + 0);
// а эти ячейки уже будут в кэше!
// и они смогут загрузиться быстро-быстро!
x += *(int *)((int)p + a + 4);
x += *(int *)((int)p + a + 8);
x += *(int *)((int)p + a + 12);
x += *(int *)((int)p + a + 16);
x += *(int *)((int)p + a + 20);
x += *(int *)((int)p + a + 24);
x += *(int *)((int)p + a + 28);
}
}
Листинг 10 [Memory/parallel.test.c] Фрагмент программы, реализующий алгоритм параллельного чтения памяти, позволяющий "разогнать" ее на максимальную пропускную способность
На P-III 733/133/100 такой трюк практически в полтора раза обгоняет алгоритм линейного чтения, достигая пропускной способности порядка 600 Mb/s, что лишь на 25% меньше теоретической пропускной способности (см. рис. graph 02). Еще лучший результат наблюдается на Athlon'е, всего на 20% не дотянувшим до идеала. Смотрите, латентность его неповоротливого чипсета практически полностью компенсирована, а сама система прямо-таки дышит мощью и летает, будто ей в вентилятор залетел шмель! И это притом, что сама тестовая программа написана на чистом Си без каких либо "хаков" и ассемблерных вставок! (То есть резерв для увеличения производительности еще есть!)
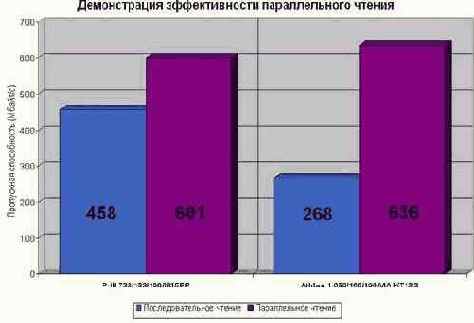
Рисунок 20 graph 0x002 Демонстрация эффективности параллельного чтения. На AMD Athlon 1050/100/100/VIA KT133 этот простой и элегантный трюк обеспечивает более чем двукратный прирост производительности. На P-III 733/133/100/I815EP выигрыш, правда, гораздо меньше – 20% – но все равно более чем ощутим