Оптимизация заполнения (инициализации) памяти
Техника оптимизации копирования памяти в целом применима и к ее инициализации – заполнению блока памяти некоторым значением (чаще всего нулями). Эта операция обычно осуществляется либо стандартной функцией языка Си memset, либо win32 функцией FillMemory. (Впрочем, на самом деле это одна и та же функция – в заголовочном файле WINNT.h макрос FillMemory определен как RtlFillMemory, а RtlFillMemory на x86 платформе определен как memset).
Подавляющее большинство реализаций функции memset использует инструкцию циклической записи в память REP STOSD, инициализирующей одно двойное слово за одну итерацию. Но, в отличие от REP MOVSD, она требует совсем другого выравнивания. Причем, об этом обстоятельстве не упоминает ни Intel, ни AMD, ни сторонние руководства по оптимизации!
Достаточно неожиданным эффектом инициализации ячеек памяти уже находящихся в кэше первого (а на P-III+ и второго) уровня является существенное увеличение производительности при выравнивании начального адреса по границе 8 байт. На P-II и P-III в этом случае за 32 такта выполняется 42 итерации записи двойных слов. Рекомендуемое же документацией выравнивание по границе 4 байт дает гораздо худший результат – за 32 такта выполняется всего лишь 12 итераций, т.е. в три с половиной раза меньше!
Это объясняется тем, что в первом случае не тратится время на выравнивание внутренних буферов и строк кэша – сброс данных происходит по мере заполнения буфера и не интерферирует с операциями выравнивания. Поскольку разрядность шины (и буфера) - 64 бита (8 байт), выбор начального адреса, не кратного 8, приводит к образованию "дыры" в 4 байта и, прежде чем свалить данные, потребуется выровнять буфер к кэшу и "закрасить" недостающие 4 байта. А это – время.
Сказанное справедливо не только для инструкции REP STOS, но и вообще для любой циклической записи – не важно слов, двойных слов или даже байт. Поэтому, многократно инициализируемые структуры данных, на момент инициализации уже находящиеся в кэше, целесообразно выравнивать по адресам, кратным восьми.
Циклическая запись в область памяти, отсутствующую в кэше – совсем другое дело. Выравнивание начального адреса по границе восьми байт, ничем не предпочтительнее четырех. Причем, на P-III начальный адрес можно вообще не выравнивать, т.к. выигрыш измеряется долями процента. Правда, на P-II цикл записи, начинающийся с адреса не кратного четырем, замедляется более чем в два раза. Такой существенный проигрыш никак нельзя не брать в расчет, даже в свете того, что парк P-II с каждым годом будет все сильнее и сильнее истощаться.
Сказанное наглядно иллюстрируют графики, приведенные на рис. 0x27 и рис. 0x028, изображающие зависимость скорости инициализации блоков памяти различного размера от кратности начального адреса на процессорах Pentium-II и Pentium-III. (см. программу memstore_align).
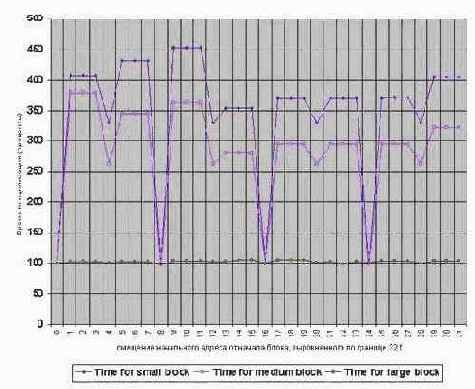
Рисунок 52 graph 0x027 График зависимости времени инициализации блоков памяти различного размера от кратности начального адреса. [Pentium-III 733/133/100]
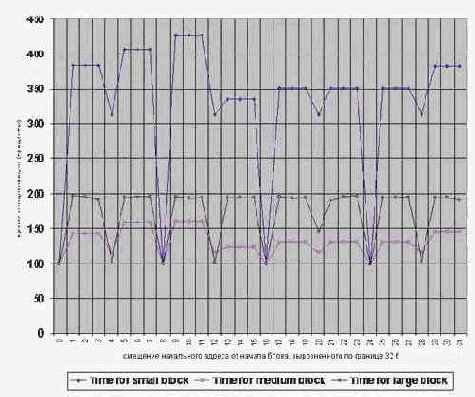
Рисунок 53 graph 0x028 График зависимости времени инициализации блоков памяти различного размера от кратности начального адреса. [CELERON-300A/66/66]
Скорость записи ячеек памяти, отсутствующих в кэше крайне непостоянна и зависит в первую очередь от состояния внутренних буферов процессора. Время инициализации небольших, порядка 4-8 килобайт блоков, может отличаться в два и более раз, особенно если операции записи следуют друг за другом всплошную – без пауз на сброс буферов. Отсутствие пауз при инициализации большого количества блоков памяти приводит к образованию "затора" – переполнению кэша второго уровня и, как следствие, значительным тормозам. И хотя средне взятый разброс скорости записи при этом существенно уменьшается (составляя порядка 5%), на графике появляются высокие пики и глубокие провалы, причем пики традиционно предшествуют провалам. Их происхождение связано с переключением задач многозадачной операционной системой, - если остальные задачи не слишком плотно налегают на шину (что чаще всего и случается) буфера (или хотя бы часть из них) успевают выгрузиться и подготовить себя к эффективному приему следующей порции записываемых данных (см.
рис.???7).
Непостоянство скорости записи создает проблемы профилирования приложений – разные участки программы поставлены в разные условия. Тормоза одного участка вполне могут объясняться тем, что предшествующий ему код до отказа заполнил все буфера и теперь инициализация происходит крайне неэффективно – т.е. выражаясь словами одного сказочного героя "когда болит горло – лечи хвост".
Серьезные проблемы наблюдаются и при оптимизации функции инициализации памяти – большой разброс замеров скорости выполнения затрудняет оценку эффективности оптимизации. Приходится делать множество прогонов для вычисления "средневзвешенного" времени выполнения.
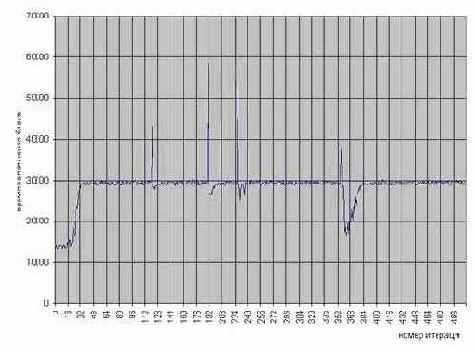
Рисунок 54 graph 0x023 График иллюстрирует непостоянность скорости записи ячеек памяти, отсутствующих в кэше (Бардовая линия). В данном примере последовательно обрабатывается 512 четырех килобайтных блока памяти. Для сравнения приведен график скорости копирования блоков памяти такого же точно размера (Синяя линия). Видно, что разброс скорости записи уменьшается при заполнении кэша второго уровня, в то время как разброс скорости копирования памяти остается постоянным. [Premium-III 733/133/100] (см. mem_mistake)
В отличие от копирования, инициализировать память всегда лучше в прямом направлении, независимо от того, как обрабатывается проинициализированный блок – с начала или с конца. Объясняется это тем, что запись ячейки, отсутствующей в кэше, не приводит к загрузке этой ячейки в кэш первого уровня – данные попадают в буфера, откуда выгружаются в кэш второго уровня. Поэтому, на блоках, не превышающих размера кэша второго уровня, никакого выигрыша заведомо не получится. Блоки, в несколько раз превосходящие L2-кэш, действительно, быстрее обрабатываются будучи проинициализированными с заду наперед, но выигрыш этот столь несущественен, что о нем не стоит и говорить. Обычно он составляет 5%-10% и "тонет" на фоне непостоянства скорости инициализации. (см. рис.???8)
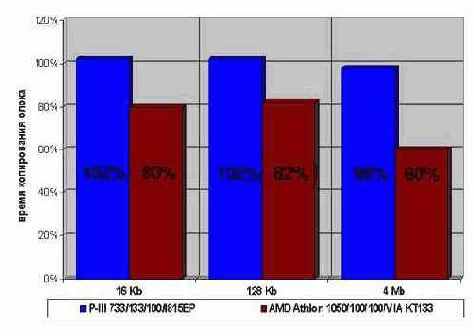
Рисунок 55 graph 0x024 Диаграмма иллюстрирует относительное время инициализации блоков памяти различного размера с последующей обработкой.
За 100% взято время инициализации штатной функции memset (синие столбики). и прямая инициализация небольшими блоками, обрабатываемыми от конца к началу (желтые столбики). [Pentium-III 733/133/100] (см. memstore_direct)
Оптимизация инициализации памяти в старших моделях процессоров Pentium. Инструкция некэшируемое записи восьмерных слов movntps, уже рассмотренная ранее, практически втрое ускоряет инициализацию памяти, при этом не "загаживая" кэш второго уровня. Это идеально подходит для инициализации больших массивов данных, которые все равно не помещаются в кэше, а вот инициализация компактных структур данных с их последующей обработкой – дело другое. На компактных блоках movntps заметно отстает от штатной функции memset, проигрывай ей в полтора-два раза, а на блоках умеренного размера, movntps хотя и лидирует, но обгоняет memset всего на 25%-30%, что ставит под сомнение целесообразность ее применения (ведь на P-II и более ранних процессорах ее нет!). (см. рис.???9)
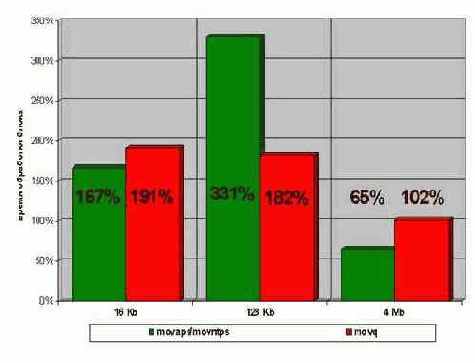
Рисунок 56 graph 0x025 Диаграмма иллюстрирует относительное время инициализации блоков памяти различного размера. За 100% взято время инициализации штатной функции memset (синие столбики). С нею состязаются инструкция копирования четверных слов movq (красные столбики) и инструкция не кэширующей записи восьмерных слов movntps (желтые и голубые столбики). Голубые столбики выражают скорость инициализации с последующей обработкой инициализированного блока.
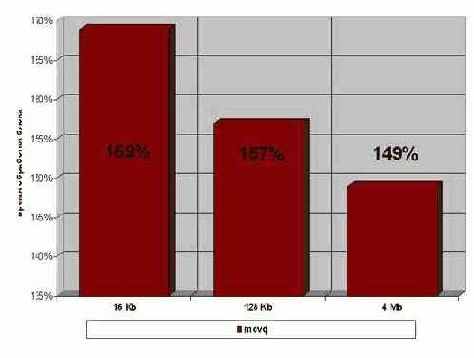
Рисунок 57 graph 0x026 Использование movq на AMD Athlon
адресация кэша - полинейная, адресация байтов в линии при помощи битов-атрибутов. любая райт-бэк операция эффективно транслируется в рид-модифай-райт.