Оптимизация копирования памяти
Для копирования памяти чаще всего используется штатная функция memcpy, входящая в стандартную библиотеку языка Си. Это очень быстрая функция, подавляющим большинством своих реализаций опирающаяся на команду циклической пересылки "REPMOVSD", копирующую по четыре байта за каждую итерацию. Но в некоторых ситуациях (например, при работе с блоками большого размера) производительности memcpy начинает катастрофически не хватать и у программистов появляется неудержимое стремление ну хоть немного оптимизировать ее.
Попробовать переписать memcpy на ассемблер? – Напрасный труд! Даже удалив весь обвязочный код, обеспечивающий копирование блоков с размером не кратным четырем, вам не удастся выиграть больше чем один-два процента! А вот правильный выбор адреса начала копируемого блока действительно ощутимо улучшает результат. Подтверждение тому – диаграмма, приведенная на рис. 0х017 и иллюстрирующая зависимость скорости копирования блоков памяти (вертикальная ось) от величины смещения относительно начала блока памяти, выделенного функцией malloc
(в данном случае возвращенный ею адрес заведомо кратен 0x10).
Смотрите – большие блоки памяти (т.е. такие, размер которых значительно превосходит кэш второго уровня), начинающиеся с адресов кратным четырем, обрабатываются практически в полтора раза быстрее, а блоки умеренного размера (целиком умещающиеся в кэше второго уровня) – практически втрое быстрее, чем блоки, начинающиеся с адресов, не кратным четырем!
И неудивительно – отсутствие выравнивания приводит к тому, что в каждом октете скопированных двойных слов, неизбежно будет присутствовать двойное слово, начинающиеся в одной кэш-линейке, а заканчивающиеся в другой. Процессоры Pentium шибко не любят такие "не правильные" слова и взыскивают за их обработку штрафные такты задержки.
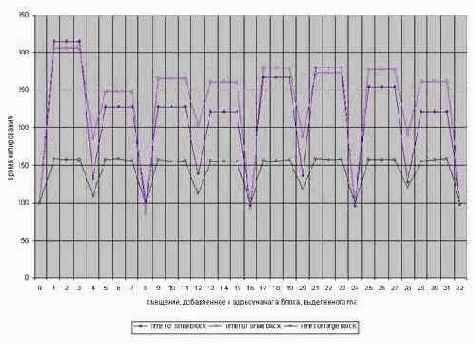
Рисунок 48 graph 0x017 Зависимость относительной скорости копирования от адреса начала блока на процессоре Pentium-III 733/1333/100. За 100% принято время копирования блоков памяти, начинающихся с адреса, кратного 0х10.
Поэтому, при интенсивном копировании строк (структур, объектов, массивов) желательно добиться, чтобы они располагались в памяти по адресам, кратным четырем. (Подробнее об этом см. "Оптимизация обращения к памяти и кэшу. Выравнивание данных").
Однако в некоторых случаях выполнить выравнивание принципиально невозможно. Это бывает в частности тогда, когда адрес копируемого объекта поступает извне, например, возвращается операционной системой. Впрочем, это не повод для расстройства – увеличив начальный адрес до величины кратной четырем, мы избежим падения производительности. А пропущенный хвост можно скопировать и отдельно. Даже если это и вызовет штрафную задержку, потери времени будут ничтожно малы, т.к. максимальная протяженность "хвоста" никогда не повышает трех байт.
В копировании больших блоков памяти есть еще один фокус. – Если память копируется слева направо (т.е. с увеличением адресов), а скопированный блок обрабатывается от начала к концу (как чаще всего и бывает), то потребуются дополнительные такты ожидания на время пока начало блока не будет загружено в кэш. Если же схитрить и копировать память справа налево (т.е. от больших адресов к меньшим), то по завершению копирования начало блока окажется в кэше и может быть моментально использовано!
Но не спешите набрасываться на инструкцию "STD\REP MOVSD", копирующую двойные слова в обратном направлении! Подсистема памяти IBM PC оптимизирована именно под прямое копирование, а на обратном теряется до десяти-пятнадцати процентов производительности. Поэтому, приходится изощряться, обрабатывая блок справа налево небольшими "кусочками", копируя каждый из них в прямом направлении. Это можно сделать, например, следующим образом:
my_memcpy(char *dst, char *src, int len)
{
int a=STEP_SIZE; // Размер копируемых "кусочков"
while(len) // Копировать пока не скопируем все
{
if (len
< a) a=len; // Если оставшийся хвост меньше размера
// копируемого "кусочка", коррекрируем
// размер последнего
dst-=a;src-=a; // Уменьшаем указатели на
// требуемую величину
memcpy(dst,src,a); // Копируем очередной кусочек
len-=a; // Уменьшаем длину оставшегося блока
}
}
Листинг 35 Оптимизированное копирование памяти с помещением начала копируемого блока в кэш (Пригодно для любых процессоров)
Единственная проблема – правильно выбрать размер копируемых кусочков. С одной стороны: чем кусочки больше – тем лучше, т.к. это уменьшает накладные расходы на "обвязочный" код. А с другой – слишком большой блок может попросту не поместиться в кэш первого уровня (на P-4 его всего лишь восемь килобайт).
Учитывая, что в кэше находится и копируемый, и скопированный блок, размер кусочков не должен превышать половины размера самого маленького их кэшей, т.е. четырех килобайт. Но эта стратегия будет не самой оптимальной для P-III, а для P-II (CELERON) и вовсе окажется проигрышной, т.к. накладные расходы на выполнение обвязочного кода пересилят выигрыш от попадания в кэш.
По мнению автора, память выгоднее всего копировать 64-128 килобайтными кусками. В среднем это дает 10%-15% ускорение по сравнению со штатной функцией memcpy, но в отдельных случаях выигрыш может быть намного большим. Впрочем, размер кусочков нетрудно задавать и опционально – через файл настроек программы, конфигурируемый конечными пользователями (или определять тип и параметры процессора автоматически).
Вот, пожалуй, и все способны оптимизации копирования памяти на младших моделях процессоров Pentium. Гораздо больше существует популярных способов "пессимизации" копирования памяти. В первую очередь хотелось бы обратить внимание на широко распространенное заблуждение, связанное с машинной инструкцией MOVSQ. Эта MMX'овая команда оперирует 64-битными (8 байтовыми) операндами, что делает ее очень привлекательной в глазах множества программистов, наивно полагающих: чем больше размер операнда, тем быстрее происходит его копирование.
На самом же деле это не совсем так. При обработке больших блоков памяти (т.е. таких, размер которых намного превышает размер L2 кэша) на быстрых процессорах (в частности P-III), вы получите не худшую производительность, а на P-II скорость даже снизиться от 1.3 до 1.5 раз! Действительно, производительность MOVSD в первую очередь определяется не быстродействием процессора, а временем доступа к памяти, поэтому при копировании больших блоков памяти MOVSQ с учетом "обвязочного" кода быстрее никак не будет.
Обработка блоков памяти умеренного размера (целиком умещающихся в L2-кэше) посредством команды MOVSQ на P-II на 10%, а на P-III даже на 40% обгоняет MOVSD! Но при дальнейшем уменьшении размера копируемых блоков ситуация меняется на диаметрально противоположную. Блоки, не вылезающие за пределы L1-кэша, с помощью MOVSQ
на P-II копируется на 40%-80% медленнее (накладные расходы на обвязочный код дают о себе знать!), а на P-III лишь на несколько процентов быстрее, чем копируемые MOVSD. (см. рис. 0х21)
Таким образом, функцию копирования, базирующуюся на команде MOVSQ, в качестве основной функции переноса памяти использовать нерационально. Она оправдает себя лишь при многократной обработке блоков порядка 0x40-0x80 килобайт на момент копирования уже находящихся в кэше. В противном случае будет намного лучше воспользоваться шатанной функцией memcpy. (К тому же следует учитывать, что MOVSQ отсутствует на ранних процессорах Pentium без MMX, парк которых до сих пор еще достаточно широк, так стоит ли отсекать большое количество потенциальных пользователей ради незначительного увеличения скорости работы вашей программы?)
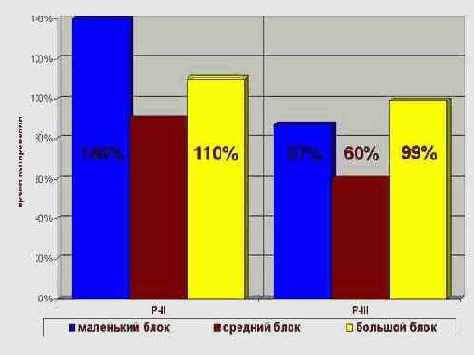
Рисунок 49 graph 0x021 Результаты тестирования функции копирования памяти четвертными словами на блоках различного размера на процессорах CELERON-300A/66/66 и Pentium-III 7333/133/100. Скорость копирования измеряется в относительных единицах в сравнении со штатной функцией memcpy, производительность которой принята на 100%.
Другое распространенное заблуждение гласит, что MOVSD вовсе не предел производительности и яко бы вручную можно создать супер-оптимизированный цикл, выполняющийся намного быстрее ее.
Действительно, линейки кэша первого уровня состоят из восьми независимых банков, которые могут обрабатываться параллельно (в частности, процессоры P-II способны за один такт обрабатывать два таких банка) и в правильно организованном цикле за вычетом обвязочного кода теоретически возможно копировать по 8 байт за каждые два такта. Инструкция REP MOVSD за это же время копирует только 4 байта.
На практике, однако, двукратного выигрыша достичь не удается – львиную долю прироста производительности "съедает" обвязочный код. Во всяком случае, автору так и не удалось создать цикл, который бы на всех моделях процессоров обгонял REP MOVSD
хотя бы на десяток-другой процентов. В лучшем случае код выполнялся не хуже, а зачастую в полтора-два раза медленнее штатной функции memcpy!
А, может быть, стоит обратиться к контроллеру DMA (про то, что современные операционные системы прикладным приложениям прав доступа к контроллеру просто не дадут, мы скромно промолчим)? Легенда об использовании DMA для копирования памяти давно уже будоражит умы программистов, но на самом деле она безосновательна. Тип передачи "память à память" ни в оригинальной IBM AT, ни в современных клонах оной не реализован. Возьмем, например, описание чипсета Intel 82801 и откроем его на странице 8-25, где содержится описание режимов передачи. Там, среди прочей полезной информации, мы найдем такие слова:
|
Bit |
Description |
|
3:2 |
DMA Transfer Type. These bits represent the direction of the DMA transfer. When the channel is programmed for cascade mode, (bits[7:6] = "11") the transfer type is irrelevant. 00 = Verify-No I/O or memory strobes generated 01 = Write-Data transferred from the I/O devices to memory 10 = Read-Data transferred from memory to the I/O device 11 = Illegal |
память". А раз его нет, то и говорить не о чем!
Оптимизация копирования в старших моделях процессоров Pentium. Команды управления кэшированием, впервые появившиеся в процессоре P-III, это, выражаясь словами известного юмориста, "не только ценный мех", но и превосходное средство ускорить копирование компактных блоков памяти вчетверо, а умеренных и больших – по крайней мере втрое!
Этот замечательный результат достигается, как ни странно, использованием всего двух команд: инструкции предвыборки данных в кэш первого (второго на P-4) уровня – prefetchnta и инструкции некэшируемой записи восьмерных (!) слов – movntps, выгружающей 128-битные операнды из SIMD-регистра в память. (Внимание: копируемые данные должны быть выровнены по 16-битной границе, в противном случае процессор сгенерирует исключение).
Поскольку, prefetchnta
– не блокируемая инструкция (т.е. молниеносно возвращающая управление задолго до своего фактического завершения), процессор может загружать очередную порцию данных из буфера-источника параллельно с переносом предыдущей порции в буфер-приемник. К тому же такая схема копирования не "загаживает" кэш второго уровня, оставляя скэшированные ранее данные в целости-сохранности, что немаловажно для большинства алгоритмов.
Но, как бы там все ни было хорошо, обязательно помните, что эти команды работают только на P-III+, а на более ранних процессорах (в т.ч. и AMD Athlon) генерируют исключение "неверный опкод".
Поскольку, компьютеры на базе P-II и P-MMX все еще продолжают использоваться (причем, достаточно широко), следует либо создавать отдельные версии программ для новых и старых процессоров (но это увеличит трудности по их тестированию и сопровождению), либо перехватывать исключение "неверный опкод" и программно эмулировать отсутствующие команды (что приведет к очень большим тормозам), либо автоматически определять процессор при старте программы и использовать соответствующую функцию копирования. (Хорошая идея поместить различные версии функций копирования в различные DLL, избавляясь от условных переходов внутри функции).
Последний способ, похоже, наиболее предпочтителен, хотя, все же и он не лишен недостатков.
Новые команды – это, конечно, хорошо, но есть ли от них хоть какая-то польза, пока на рынке не появятся компиляторы, обеспечивающие их поддержку? Ну, во-первых, такие компиляторы уже есть и распространяются самой Intel, а, во-вторых, ничто не мешает программисту использовать ассемблерные вставки в своем любимом компиляторе (правда, не все умеют программировать на ассемблере).
Будет большим заблуждением считать, что поддержка компилятором новых команд автоматически увеличит производительность приложения и вся оптимизация сведется к тривиальной перекомпиляции. Новые команды предлагают новые концепции программирования, что требует кардинального пересмотра алгоритмов программы. А решать алгоритмические задачи до сих пор способен лишь человек – компиляторам это не "по зубам".
Писать программы на ассемблере – тоже не лучший выход. Решение, предложенное Intel, носит компромиссный характер и заключается во введении встроенных операторов (intrinsic), функционально эквивалентных командам процессора, но обладающих высокоуровневым интерфейсом с "человеческим лицом". Например, конструкция "void _mm_prefetch(char *a, int sel)" на самом деле является не функцией, а завуалированным вызовом команды prefetchx. Встретив ее в тексте программы, компилятор отнюдь не станет вызывать подпрограмму, а непосредственно вставит соответствующую инструкцию в код, минимилизируя накладные расходы. (Некоторые операторы заменяются не на одну, а на целую группу совместно употребляемых машинных команд, но сути дела это не меняет).
Подробное описание intrinsic'сов и соответствующих им машинных инструкций можно найти в "Интел Инстракшен Сет" (Instruction Set Reference) и справочном руководстве, прилагаемом к компилятору (Intel C/C++ Compiler User's Guide With Support for the Streaming SIMD Extensions 2). Поясняющие примеры, приведенные в руководстве по оптимизации (Intel Architecture Optimization Reference Manual), в подавляющем большинстве написаны на Си с intrinsic'ами, и для их понимания необходимо знать: какой intrinsic какой команде процессора соответствует (их мнемоники очень часто не совпадают).
Поэтому, обращаться к таблице соответствий придется не зависимо от того: программируете ли вы на чистом ассемблере или Си (Фортране).
Хорошо, Intel справилась с проблемой, но как быть пользователям других компиляторов? Не отказываться же от своих любимых продуктов в угоду прогрессу (тем более, что Intel предоставляет компиляторы всего лишь двух языков – Си\Си++ и Фортрана, к тому же распространяет их отнюдь не бесплатно)!
Выход состоит в использовании ассемблерных вставок, а точнее даже не ассемблерных, а машинно-кодовых, поскольку сомнительно, чтобы ваш любимый транслятор понимал мнемоники, придуманные после его создания. В ассемблерах MASM и TASM ручной ввод кода обычно осуществляется через директиву "DB", а в компиляторах Microsoft Visual C++ и Borland C++ для той же цели служит директива "emit". К сожалению, синтаксис ее вызова различен для каждого из компиляторов, что приводит к проблемам переносимости.
Так, Microsoft Visual C++ предваряет emit одиночным символом прочерка и требует обязательного его помещения в ассемблерный блок. Например:
main()
{
__asm
{
; "рукотворное" создание инструкции INT 0x66 (опокд – CD 66)
_emit 0xCD
_emit 0x66
}
}
Компилятор Borland C++, напротив, предписывает окантовывать emit двойным символом прочерка с обеих сторон и ожидает его появления вне ассемблерного блока. Например:
main()
{
; "рукотворное" создание инструкции INT 0x66 (опокд – CD 66)
__emit__(0xCD, 0x66);
}
Разумеется, ручной ввод машинных кодов команд – утомительное и требующее определенной квалификации занятие. Проблема в том, что "Интел инстракшен сет" содержит лишь базовые опкоды инструкций, без перечисления всех возможных способов адресации. Например, опкод инструкции prefetchnta
выглядит так: 0F 18 /0. Если попытаться задать его с помощью emit как "__emit__(0xF, 0x18, 0x0)", то ничего не получится! (Кстати, это частая ошибка начинающих).
Ведь prefetchnta
ожидает операнда- указателя на адрес памяти, по которому следует произвести предвыборку. Где же он тут? А вот где: обратите внимание, что последний байт опкода инструкции предварен косой чертой – это обозначает, что приведено не все содержимое байта, а лишь те биты, которые хранят опкод инструкции. Остальные же определяют тип адресации, указывая процессору: где именно следует искать ее операнды (операнд).
В рамках данной книги вряд ли было бы целесообразно подробно рассказывать о формате машинных команд, поэтому автору ничего не остается, как отослать всех интересующихся к первым восьми страницам "Интел Инстракшен Сет", где это подробно описано. Во всяком случае, реализации двух необходимых для оптимизации копирования памяти команд, приведены ниже.
// Функция предвыбирает 32-байтовую строку в L1-кэш на P-III
// и 128-байтовую строку в L2-кэш на P-4
// Аналог _mm_prefetch((char*)mem, _MM_HINT_NTA)
__forceinline void __fastcall __prefetchnta(char *x)
{
__asm
{
mov eax,[x]
; prefetchnta [eax]
_emit 0xF
_emit 0x18
_emit 0x0
}
}
// Функция копирует 128-бит (16-байт) из src
в dst.
// Оба указателя должны быть выровнены по 16-байтной границе
// Аналог _mm_stream_ps((float*)dst,_mm_load_ps((float*)&src))
void __forceinline __fastcall __stream_cpy(char *dst,char *src)
{
__asm
{
mov eax, [src]
mov edx, [dst]
; movaps xmm0, oword ptr [eax]
_emit 0xF
_emit 0x28
_emit 0x0
; movntps oword ptr [edx], xmm0
_emit 0xF
_emit 0x2B
_emit 0x2
}
}
Листинг 36 Пример реализации команд процессора P-III+ ассемблерными вставками на Microsoft Visual C++.
Пару слов о способах вызова "рукотворных" команд. Это только кажется, что все просто, а на самом же деле, на этом пути сплошное нагромождение ловушек, трудностей и проблем. Вот только некоторые из них…
Достаточно очевидно, что оформлять одиночные процессорные команды в виде cdecl- или stdcall-функций невыгодно – зачем разбрасываться командами процессора? (Хотя, к чести P-III/P-4 стоит сказать, что при его скорости накладными расходами на вызовы функцией можно безболезненно пренебречь).
Отсюда и появляется квалификатор __forceinline, предписывающий компилятору встраивать вызываемую функцию непосредственно в тело вызывающей.
Правда, компилятор – животное упрямое и душа его – потемки. Встраиванию функции препятствует целый ряд противопоказаний (см. описание квалификатора inline
в прилагаемой к компилятору документации). Так, например, встраиваемыми не могут быть голые (naked) функции – т.е. функции без пролога и эпилога, часто используемые программистами, не полагающимися на удаление избыточного кода оптимизатором.
Кстати, об оптимизаторе. Соглашение Microsoft о быстрых вызовах (см. ключевое слово __fastcall) предписывает передавать первый аргумент функции в регистре ECX, а второй – в EDX. Так почему же в выше приведенных примерах автор перепихивает содержимое первого регистра в EAX, если можно преспокойно обратиться к ECX? Увы, коварство оптимизатора этого не позволяет. Обнаружив, что на аргументы функции явных ссылок нет (и, конечно же, благополучно забыв о регистрах), оптимизатор думает – а на кой передавать эти аргументы, если они не используются? И не только думает, но и не передает! В результате, в регистрах оказывается неинициализированный мусор, и функция, естественно, не работает! К сожалению, любое обращение к аргументам из ассемблерного блока приводит к автоматическому созданию фрейма, адресуемого через регистр EBP, т.е., аргументы функции передаются не через регистры, а через локальные стековые переменные!
Словом, избежать накладных расходов таким путем, увы, не удается… Впрочем, эти расходы не слишком велики и ими, скрепя сердце, можно пренебречь.
С алгоритмом оптимизированного копирования тоже не все безоблачно. Пример реализации, приведенный в "Intel® Architecture Optimization Reference Manual" – руководству по оптимизации под P-II и P-III (Order number 245127-001), содержит множество ошибок (вообще такое впечатление, что это руководство готовили в страшной спешке, – вот что значит первая ревизия!). К тому же, он не оптимален под P-4, а пример, приведенный в руководстве оптимизации по P-4, не оптимален под P-III! Поэтому, просто скопировать код программы в буфер обмена и откомпилировать – не получится.
Хочешь – не хочешь, а приходится доставать мозги с полки и мыслить самостоятельно. Значит, так…
На первом месте, конечно же, должен быть цикл предвыборки, дающий процессору задание на загрузку данных из основной памяти в кэш первого уровня (второго на P-4). Затем, загруженные в кэш данные могут быть мгновенно (в течении одного такта) прочитаны и занесены в SIMD-регистр, по эстафете передаваемый инструкции некэшируемой записи для выгрузки в память. (Использование промежуточного регистра объясняется тем, что адресация типа "память à
память" в микропроцессорах Intel 80x86 отродясь отсутствует).
Остается найти оптимальную стратегию предвыборки и записи. Решение, первым приходящее на ум, – перемежевать операции переноса данных с их предвыборкой, неверно. Правда, объяснить: почему оно неверно "на пальцах", не углубляясь в тонкости реализации шинных транзакций, невозможно. В общих чертах дело обстоит так: системная шина у процессора одна, но запросы на чтение/запись памяти делятся на множество фаз, которые могут перекрывать друг друга. Полного параллелизма в такой схеме, естественно, не достигается и неупорядоченная обработка запросов несет свои издержки. Уменьшение количества транзакций между чтением и записью данных позволяет значительно ускорить доступ к памяти, что, в свою очередь, существенно увеличивает производительность системы.
Следовательно, целесообразнее выполнять предвыборку в одном, а копировать память в другом цикле. Но, вот вопрос, – какими кусками "нарезать" память? В приведенном ею примере Intel рекомендует выбрать размер блока равным размеру кэша первого уровня для P-III и половине кэша второго для P-4 (т.к. у него команда предвыборки умеет загружать данные только в этот кэш). В то же время, описывая команду предвыборки в руководстве по оптимизации под P-4, Intel остерегает пересекать 4-килобайтовую границу страниц при предвыборке. (Такое впечатление, что авторы технической документации из Intel понимают в выпускаемых их фирмой процессорах меньше, чем сторонние разработчики).
Итак, у нас имеются два противоречащих друг другу утверждения, – какому же из них верить? Но зачем, собственно, верить? Наука – она тем от религии и отличается, что в первую очередь полагается не на авторитеты и логические умозаключения, а на эксперимент. Эксперимент же недвусмысленно скажет, что наилучшая производительность достигается при предвыборке блоков размером в 4 килобайта – т.е. одной страницы, а при увеличении размера начинает стремительно падать.
Так, с этим мы разобрались. Идем дальше. Реализация цикла предвыборки (между нами говоря) представляет собой достойный увековечивания пример как не надо программировать. Смотрите сами: "for (j=kk+4; j<kk+CACHESIZE; j+=4)". То, что вместо CACHESIZE
должно стоять PAGESIZE, мы уже выяснили, но вот величина шага приращения цикла очень интересна. Теоретически она должен быть равна размеру предвыбираемой строки – 32 байта на P-III и 128 байт на P-4. Откуда же здесь взялась четверка? Дело в том, что данный пример копирует массив, состоящий из элементов типа double, каждый из которых имеет размер 8 байт (про sizeof парни из Intel, конечно же, забыли), а 8 x 4 == 32! А если придется копировать данные другого типа? Так не лучше ли перейти от частностей к бестиповым указателям void? К тому же, данная реализация процессорно-зависима и не оптимальна на P-4. Правильным решением будет определять тип процессора при старте программы и выбирать соответствующий ему шаг цикла – 32 байта на P-III и 128 байт на P-4.
Следующий на очереди цикл копирования памяти. В Intel'ом примере допущена еще одна грубая ошибка (не иначе, как документацию писали под пивом) – "for (j=kk; j<kk+CACHESIZE; j+=4)" – конечно же, здесь должно быть не CACHESIZE, а, по крайней мере, CACHESIZE/sizeof(double), а точнее даже – PAGESIZE/sizeof(double). Этот ляп исправлен лишь в руководстве по оптимизации под P-4, где вместо CACHESIZE
фигурирует NUMPERPAGE
– количество элементов на страницу. Это уже лучше, но все же остается непонятным стремление авторов документации любой ценой избежать обращения к sizeof.
Тело цикла состоит из нескольких подряд идущих команд переноса 128-битного (16-байтового) блока памяти – в примере из руководства по P-III их два, а P-4 – аж восемь! Вакх! Зачем нам столько, когда достаточно и одной? А затем – чем больше операций копирования выполняется в каждой итерации цикла, тем меньше накладные расходы на организацию этого цикла. Различие же в количестве операций в обоих процессорах объясняется тем, что на P-III размер кэш-линий равен 32 байтам, а на P-4 – 128.
Поскольку, каждая операция копирования переносит 16 байт памяти, легко видеть, что в обоих случаях за одну итерацию цикла кэш-линия обрабатывается целиком, а задержки, связанные с поддержкой цикла, приурочиваются к переходу на следующую кэш–линию, что обеспечивает максимально возможную производительность. Любопытно, что цикл переноса памяти, оптимизированный под P-4, ничуть не хуже чувствует себя и на P-III, а вот пример, оптимизированный под P-III, попав на P-4, показывает далеко не лучший результат. Универсальным решением будет перенос 128–байтного блока памяти за каждую итерацию – это оптимально для обоих процессоров.
Теперь остается решить лишь технические проблемы. Во-первых, рассмотреть случай копирования блока памяти, размер которого не кратен размеру страницы – оставшийся хвост последней страницы придется переносить отдельно. Во-вторых, команда некэшируемой записи требует (а команда чтения рекомендует) чтобы данные были выровнены по 16-байтовой границе. В противном случае генерируется исключение. Вообще-то, требование выравнивания можно просто оговорить в спецификации функции, но будет лучше, если функция автоматически выровняет переданные ей указатели, не забыв, конечно, скопировать остаток обычным способом.
И, наконец, последнее: в фирменном примере присутствует бессмысленная на первый взгляд конструкция: "temp = a[kk+NUMPERPAGE]; // TLB priming" – для чего она предназначена? Программистам, знакомым с защищенным режимом, должно быть известно, что для трансляции виртуальных адресов в физические, процессор обращается к специальной структуре данных – страничному каталогу.
Страничный каталог формируется операционной системой и хранится в оперативной памяти. А оперативная память – это тормоза. Поэтому, данные страниц, к которым обращались в последнее время, автоматически запоминаются в специальном кэше – буфере ассоциативной трансляции (TLB - Transaction Look aside Buffer). Разумеется, данных о станицах, к которым еще не обращались, в TLB нет. Конструкция "temp = a[kk+NUMPERPAGE];"
как раз и загружает данные следующей копируемой страницы в TLB. Правда, остается непонятным, почему Intel выполняет упреждающую загрузку в TLB с одного лишь буфера-источника, забывая о приемнике. К тому же, загрузка данных страницы в TLB чтением ячейки памяти – блокируемая инструкция. Так какая разница: когда она произойдет сейчас или позже в ходе реального обращения к странице? (Правда, можно предположить, что с учетом внеочередного исполнения команд на P-III+ данная конструкция все же будет не блокируемой, но экспериментально подтвердить эту гипотезу не удается). К сожалению, это рождает проблему выхода за границы копируемого массива (ведь в последней итерации цикла мы обращаемся к возможно не существующей странице за его концом и если не предпринять дополнительных мер – операционная система может выбросить исключение, а дополнительные меры – это лишние накладные расходы). Ко всему прочему, оптимизирующий компилятор просто уничтожит бессмысленное (с его точки зрения!) присвоение – ведь переменная temp никак не используется в программе! Автором было экспериментально установлено, что удаление этой конструкции в не ухудшает производительности, поэтому, в своих разработках он рискнул ее не использовать.
Приведенный ниже пример реализации функции турбо-копирования для оптимизации под конкретный процессор использует два определения: _PAGE_SIZE, в обоих случаях равное 4 Кб, и _PREFETCH_SIZE – равное 32 байтам для P-III и 128 для P-4. Адреса источника и приемника должны быть выровнены по 16-байтовой границе, а размер копируемого блока – кратен размеру страницы.
Эти ограничения объясняются стремлением максимально упростить листинг для облегчения его понимания.
_turbo_memcpy(char *dst, char *src, int len)
{
int a, b, temp;
for (a=0; a < len; a += _PAGE_SIZE)
{
// Предвыбираем
temp = *(int *)((int) src + a + _page_size);
for (b = a; b < a + _PAGE_SIZE; a += _PREFETCH_SIZE)
__prefetchnta(src+b);
for (b = a; b < a + _PAGE_SIZE; b += 16 * 8)
{
__stream_cpy(dst + b + 16*0, src + b + 16*0);
__stream_cpy(dst + b + 16*1, src + b + 16*1);
__stream_cpy(dst + b + 16*2, src + b + 16*2);
__stream_cpy(dst + b + 16*3, src + b + 16*3);
__stream_cpy(dst + b + 16*4, src + b + 16*4);
__stream_cpy(dst + b + 16*5, src + b + 16*5);
__stream_cpy(dst + b + 16*6, src + b + 16*6);
__stream_cpy(dst + b + 16*7, src + b + 16*7);
}
}
return temp;
}
Листинг 37 [Cache/_turbo_memcpy.size.c] Функция турбо-копирования памяти, использующая новые команды управления кэшированием процессора P-III+.
Результаты тестирования функции турбо-копирования на блоках памяти различного размера приведены на рис. 0x02 (К сожалению, процессора P-4 в данный момент не оказалось под рукой и автору пришлось ограничится одним лишь P-III). Впечатляющее зрелище, не так ли? (Особенно в свете того, что функция копирования написана на чистом Си). Но и это еще не предел!
Во-первых, переписав код на ассемблер, можно на несколько процентов увеличить его производительность, добившись, по крайней мере, пяти кратного превосходства над штатной memcpy при копировании небольших блоков.
Во-вторых, представляет интерес рассмотреть частные случаи оптимизации. Например, если копируемые данные уже находятся к кэше (что очень часто и происходит при обработке блоков данных небольших размеров), цикл предвыборки можно исключить. (Особенно это актуально для программ, выполняющихся под P-4, команда предвыборки которого загружает данные в кэш второго, а не первого уровня).
При копировании блоков большого размера, обрабатываемых с начала, напротив, целесообразно использовать дополнительный цикл предвыборки, загружающий скопированные данные в кэш.
Впрочем, оптимальная стратегия копирования очень сильно зависит от конкретной ситуации и универсальных решений не существует – каждая программа требует своего подхода. Поэтому, не будем давать готовых решений, оставляя читателям полную свободу творчества.
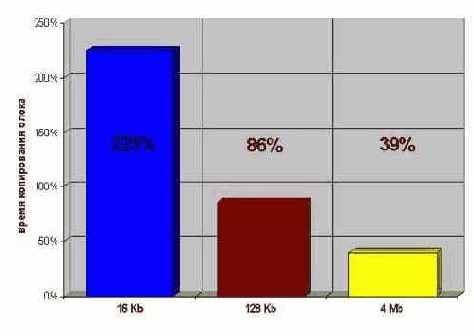
Рисунок 50 graph 0x020 Результаты тестирования производительности функции турбо-копирования на блоках памяти различного размера под процессором Pentium-III 733/133/100. Скорость копирования измеряется в относительных единицах в сравнении со штатной функцией memcpy, производительность которой принята за 100%.
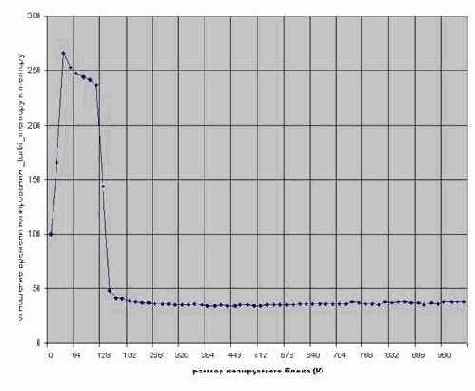
Рисунок 51 graph 0x022 График зависимости производительности функции турбо-копирования от размера предвыбираемого блока. [Pentium-III 733/133/100]
Заключение
…полученными результатами можно по праву гордиться: пятикратное ускорение – это что-то! Однако, копирование – не единственная базовая операция с памятью. Две другие – инициализация (заполнение) и сканирование (поиск) ничуть не в меньшей степени влияют на производительность, но требуют к себе совсем иных подходов, нежели копирование.
Об этом (и многом другом) мы и поговорим в следующей статье…
P.S. Да не будет сочтены небольшие придирки к Intel'овской документации за наезд на компанию. Автор, являясь горячим поклонником Intel, далек от мысли бросать в нее камни, но вот пару острых шуточек в ее адрес, все же себе позволяет.