Определение предпочтительной кэш-иерархии
Народная мудрость "положишь подальше – возьмешь поближе" в отношении предвыборки данных практически всегда неверна. Чем ближе к процессору в кэш-иерархии расположены данные, тем быстрее они могут быть получены. Т.е. если уж и осуществлять предвыборку – то предпочтительнее всего в кэш первого уровня (редкие исключения из этого правила будут рассмотрены ниже).
Если данные используются многократно, их предвыборку желательно осуществлять в кэш-уровни всех иерархий, – тогда при вытеснении из кэша первого уровня, данные за короткое время будут получены из кэша второго уровня и процессору не придется обращаться к медленной оперативной памяти. Напротив, однократно используемые данные (равно как и данные, гарантированно не вытесняемые из кэша первого уровня), загружать в кэш второго уровня нецелесообразно, особенно если в нем в это время хранится нечто полезное.
Сказанное в высшей степени справедливо для P-III, но не совсем верно в отношении P-4 (вернее, не верно совсем). Поскольку, вместо загрузки данных в кэш первого уровня, P-4 помещает их в первый банк кэша второго уровня, особенной свободы выбора у программистов и нет. И единственное отличие между командами prefetchnta и prefetchtx
заключается в том, что prefetchnta не может вытеснить из кэша второго уровня более одной восьмой объема его данных. (А по закону бутерброда вытесняются именно те данные, которые вам нужнее всего).
На K6 (VIA C3) никаких проблем с определение предпочтительной кэш-иерархии нет, поскольку нет и самой возможности ее выбора – данные всегда загружаются в кэш-уровни всех иерархий, вытесняя содержимое L2-кэша еще интенсивнее, чем на P-4! Поэтому, разработчики, оптимизирующие свои программы под K6\C3 не найдут в этой главе для себя ничего интересного.
Но довольно теории, перейдем к конкретным примерам. Вернемся к листингу N???2. Достаточно очевидно, что совершенно все равно: какой командой предвыборки пользоваться – prefetchnta или prefetcht0, поскольку к каждой ячейке обращение происходит лишь однократно, а в кэше второго уровня не хранится никаких ценных данных, которые было бы жалко вытеснять. (Впрочем, не стоит забывать, что в многозадачных операционных системах кэш приходится делить между несколькими приложениями и без острой надобности затирать его содержимое, право же, не стоит).
Достаточно лишь воспользоваться командой предвыборки не временных данных, убивая одним выстрелом двух зайцев наповал. Во-первых, предвыборка избавляет нас от ожидания загрузки ячеек блока BLOCK2, а, во-вторых, она позволяет подгружать блок BLOCK2 напрямую в кэш первого уровня (на P-4 в первый банк кэша второго уровня), не затирая содержимого блока BLOCK1, хранящегося в L2-кэше. (На P-4, – увы, – блок BLOCK1 все же будет частично затираться).
Следовательно, в данном случае выгоднее всего воспользоваться инструкцией prefetchnta, а не prefetchtx, поскольку она не затирает (на P-4 минимально затирает) кэш второго уровня:
for(...)
for(c=0;c<BLOCK2_SIZE;c+=STEP_SIZE)
{
// Обрабатываем блок BLOCK1 (находящийся в L2-кэше).
// Предвыборка в L1 кэш не нужна, т.к. это все равно
// не увеличит производительности, ввиду того, что на
// P-III время доступа к кэшу второго уровня
// пренебрежительно мало, а P-4 и вовсе не позволяет
// грузить данные в кэш первого уровня
b+=p1[d]; if ((d+=32) > BLOCK1_SIZE) d=0;
// Перед тем как заняться вычислениями отдаем команду на
// предвыборку данных блока BLICK2 в L1-кэш (в L2 на P-4)
// Во-первых, избавляясь тем самым от ожидания загрузки
// данных из медленной оперативной памяти, а во-вторых,
// предотвращая вытеснение данных блока BLOCK1 из L2-кэша
_prefetchnta(p2+c+STEP_SIZE);
// Обратите внимание, что загружаются данные, обращение
// к которым произойдет только в следующей итерации.
// Почему именно так? Дело в том, что время загрузки
// превышает время вычисления "b+=b % (c+1)" и...
// Загружая данные следующей итерации, мы теряем лишь
// первую итерацию цикла, а не через одну,
// как может показаться в начале, т.к. этот прием вполне
// законен и обеспечивает максимальный прирост
// быстродействия.
b+=b % (c+1);
// Теперь данные загружаются из L1-кэша! (из L2 на P-4)
b+=p2[c];
}
Листинг 23 Оптимизированный вариант с использованием предвыборки не временных данных
На P-III использование prefetchnta на 40% увеличивает производительность, в то время как prefetcht0 – на 20%, на prefetcht1 на 50% уменьшает ее, что и не удивительно, т.к. предвыборка временных данных приводит к вытеснению из кэша второго уровня содержимого блока BLOCK1, ничего не давая взамен. (см. рис. 0х016)
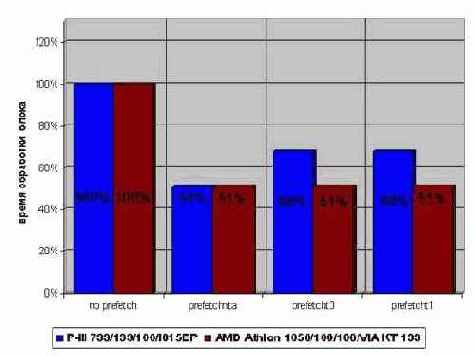
Рисунок 41 graph 0x016 Влияние различных типов предвыборки на производительность различных приложений