Обработка памяти байтами, двойными и четвертными словами
В своей повседневной практике программисты сталкиваются с самыми различными типами данных: байтами, двойными и четвертными словами… Какие же из них наиболее эффективны? Среди программистов нет единого мнения на этот счет. Одни руководства рекомендуют обрабатывать большие блоки памяти двойными словами и советуют навсегда забыть, что такое "байт". Другие же соблазняют командами мультимедийной обработки данных, способными "заглатывать" по крайней мере 64 бита (целое четвертное слово!) за один раз. Ближе всего к истине подобралось первое утверждение, да и то с некоторыми оговорками.
Несложная тестовая программа (см. [Memory/DWORD.c] – исходный текст который здесь не приводится ввиду ее простоты) убедительно доказывает, что чтение памяти двойными словами действительно, происходит на ~30% – ~40% быстрее побайтового чтения (см. рис. graph 25). А вот чтение памяти четвертными словами (с использованием команды MOVQ) на P?III 733/133/100/I815EP отстает от двойных слов на добрых 25%! Правда, на AMD Athlon 1050/100/100/VIA KT133 разрыв в производительности составляет всего ~5%, но это никак не меняет сути вещей. Чтение больших блоков памяти четвертными словами крайне нецелесообразно. (Вот компактные блоки памяти, – другое дело, но об этом мы поговорим позже, - см. "Кэш").
Интересная ситуация складывается с записью памяти. И байты, и двойные слова в этом случае оказывается одинаково эффективны! Поэтому, при записи данных смело выбирайте любой тип данных, – какой вам больше приходится по душе (читай: какой лучше подходит для описания конкретного алгоритма). Запись памяти четверными словами, как вы уже наверняка догадались, менее выгодна. И это действительно так! Забавно, но теперь наибольший разрыв в производительности наблюдается не на P?III (как это было при чтении памяти), а на AMD Athlon, который в 1,6 раз проигрывает двойными словам по скорости обработки.
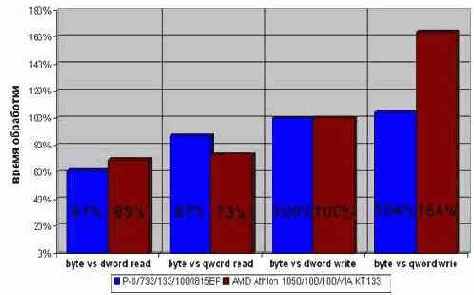
Рисунок 34 graph 25 Сравнительная эффективность чтения/записи больших блоков памяти байтами, двойными и четверными словами.
Как видно: чтение памяти лучше всего осуществлять двойными словами, а запись – либо байтами, либо двойными словами. Обработка памяти четвертными словами всегда осуществляется наименее эффективно
Обработка байтовых потоков двойными словами.
В некоторых случаях байтовые потоки данных могут (не без ухищрений конечно) обрабатываться непосредственно двойными словами, что значительно (см. рис. graph 26) увеличивает производительность обрабатывающего их приложения.
Рассмотрим следующий пример, шифрующий байты тривиальной операцией XOR по постоянной маске:
simple_crypt(char *src, int mask, int n)
{
int a;
for (a = 0; a < n; a++)
src[a]^=mask;
}
Листинг 22 Пример обработки байтового потока
Поскольку, все байты обрабатываются однородно, – почему бы ни попробовать обрабатывать четыре байта одной командой? В данном случае для этого достаточно лишь "размножить" маску шифрования, скопировав ее в остальные три байта двойного слова.
Правда, еще потребуется предусмотреть возможность обработки блоков, размер которых не кратен четырем (а что, может же сложиться такая ситуация?). Кстати, это очень просто! Достаточно, получив остаток от деления размера блока на четыре, зашифровать оставшиеся "хвост" (если он есть) "вручную", – т.е. по байтам.
Это может выглядеть, например, так:
optimized_simple_crypt(char *src, int mask, int n)
{
int a;
// размножаем байтовую маску для получения двойного слова
supra_mask = mask+(mask<<8)+(mask<<16)+(mask<<24);
// обрабатываем байты двойными словами
for (a = 0; a < n; a += 4)
{
*(int *)src ^= supra_mask; src+=4;
}
// обрабатываем оставшийся "хвост" (если он есть)
for (a = (n & ~3); a < n; a++)
{
*src ^= mask; src += 1;
}
}
Листинг 23 Оптимизированный пример обработки байтового потока двойными словами
Разумеется, такой трюк применим не только к побайтовой шифровке! Оптимизации поддаются также алгоритмы копирования, инициализации, сравнения, поиска, обмена… словом все однородные способы обработки данных.