Комбинирование операция записи с вычислительными операциями
Буферизация записи позволяет откалывать физическую выгрузку данных в сверхоперативную и/или основную оперативную память до того момента, когда процессору это будет наиболее "удобно". До тех пор, пока в наличии имеется по крайней мере один свободный буфер, такой прием существенно увеличивает производительность. В противном случае, процессор вынужден простаивать в ожидании выгрузки содержимого буферов и тогда запись с буферизацией ведет себя как обычная запись.
Другая не менее значимая функциональная обязанность буферов – упорядочивание записи. Данные, поступающие в буфера, неупорядочены и попадают в них по мере завершения команд микрокода. Здесь они сортируются и вытесняются с буферов уже в порядке следования оригинальных машинных команд программы.
Отсюда: переполнение буферов автоматически влечет за собой блокировку кэш-памяти,– до тех пор, пока не завершится выгрузка данных, вызвавших кэш-промах, все остальные попытки записи в память (независимо завершаются ли они кэш-попаданием или нет) будут временно заблокированы. Не очень-то хорошая перспектива, не правда ли?
Этой ситуации можно избежать, если планировать обработку данных так, чтобы скорость заполнения буферов не превышала скорости их выгрузки в кэш и/или оперативную память. Процессоры P-II и P-III содержат двенадцать 256-битных буферов, каждый из которых может соответствовать любой 32-байтовой области памяти, выровненной по границе 32 байт. Другими словами, буфера записи представляют собой 384-байтовый полностью ассоциативный кэш, состоящий из 12 кэш-линеек по 32 байта каждая. Так, надеюсь, будет понятно?
Процессор P-4 содержат аж 24 буфера записи, каждый из которых, по всей видимости, вмещает 512 бит данных.
Процессор AMD Athlon, так же, как и P-II/P-III содержит 12 буферов записи, совмещенных с буферами чтения. Об их длине в документации ничего не говориться (или просто я не нашел?), но можно предположить, что вместимость каждого из буферов составляет 64 байта.
Конечно, это вдовое меньше, чем у P-4, но AMD Athlon в отличии от своего конкурента, всегда выгружает содержимое буферов в кэш-первого уровня, в то время как процессоры P6 и P-4 при отсутствии записываемых данных в кэше первого уровня, выгружают их в кэш второго.
Трудно сказать, чья политика лучше. С одной стороны, при записи большого количества данных, обращений к которым в обозримом будущем не планируется, Intel заметно выигрывает, поскольку не "засоряет" кэш-первого уровня. С другой: выгрузка буферов на AMD Athlon происходит несколько быстрее, что уменьшает вероятность возникновения "заторов". Но, в то же время, 256-битная шина P-III и P-4, соединяющая кэш первого с кэшем второго уровня, практически стирает разницу в их производительности и буфера выгружаются даже с большей скоростью, чем на Athlon. Правда, Athlon, умеющий вытеснять содержимое кэша первого уровня параллельно с записью в него новых данных, от такого расклада вещей ничуть не страдает и… В общем, этот поединок детей двух гигантов процессорной индустрии можно продолжать бесконечно. Да и есть ли в этом смысл? Ведь при оптимизации программы все равно приходится закладываться на худшую конфигурацию, т.е. в данном случае на двенадцать 32-байтовых буферов записи.
Посмотрим (см. "Intel® Architecture Optimization Reference Manual Order Number: 245127-001"), что говорит Intel по этому поводу. "Write hits cannot pass write misses, so performance of critical loops can be improved by scheduling the writes to memory. When you expect to see write misses, schedule the write instructions in groups no larger than twelve, and schedule other instructions before scheduling further write instructions"
("Попадания /* hit */ записи не преодолевают промахи записи, поэтому, производительность критических циклов может быть увеличена планированием записей в память. Когда вы ожидаете промах записи, объединяйте инструкции записи в группы не более чем по двенадцать
и разделяйте их группами других инструкций").
Эта рекомендация содержит по крайней мере три неточности. Первая и наименее существенная из них: на самом деле, количество членов группы может быть и более двенадцати, ведь выгрузка буферов осуществляется параллельно с их заполнением. Объединение 14 команд записи не несет никакого риска, во всяком случае при выполнении программы под P-II/P-III/AMD Athlon и уже тем более P-4.
Другой момент. Под словом "двенадцать" авторы документации подразумевали "двенадцать команд записи с различными установочными адресами". На P-II/P-III в установочный адрес входят биты с 4 по 31 линейного адреса, а на P-4/AMD Athlon – с 5 по 31. Т.е. при последовательной записи 32-разрядных значений, "штатная" численность каждого группы команд составляет не двенадцать, а девяносто шесть "душ".
Наконец, третье и последнее. Поскольку, все записываемые данные в обязательном порядке проходят через буфера, предыдущее замечание не в меньшей степени справедливо и для модификации данных, уже находящихся в кэш-памяти перового уровня. С другой стороны, к данным, еще не вытесненным из буфера, можно обращаться многократно и "записью" это не считается.
Боюсь, что своими уточнениями я вас окончательно запутал… Но блуждание в трущобах непонимания, все таки лучше столбовой дороги грубого заблуждения. Давайте рассмотрим следующий пример Как вы думайте, можно ли назвать его оптимальным?
/*------------------------------------------------------------------------
*
* НЕОПТИМИЗИРОВАННЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
// 192 ячейки типа DWORD дают в сумме 776 байт памяти,
// что вдвое превышает емкость буфером записи на
// процессорах PII/PIII. Где-то на половине исполнения
// возникнет затор и дальнейшие операции записи будут
// исполняться гораздо медленнее, т.е. им придется
// всякий раз дожидаться выгрузки буферов
for(a = 0; a < 192; a += 8)
{
// для устранения накладных расходов цикл
// должен быть развернут, иначе его
// расщепление снизит производительность
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
// делаем некоторые вычисления
for(b = 0; b < 66; b++)
x += x/cos(x);
Листинг 17 [Cache/write_sin.c] Кандидат на оптимизацию посредством совмещения команд записи с вычислительными операциями
Конечно же, цикл for a
на P-II/P-III исполняется весьма не оптимально. Даже если предположить, что на момент его начала все буфера девственно чисты (что вовсе не факт!), не успеет он перевалить за половину, как свободные буфера действительно кончатся и начнутся сильные тормоза, поскольку все последующие операции записи будут вынуждены ждать освобождения буферов. Ввиду постоянной занятости шины ждать придется довольно долго. Зато потом, в вычислительном цикле, она (шина) будет простаивать. Экий не рационализм!
Давайте реорганизуем наш цикл так, разбив его на несколько под–циклов, каждый из которых заполнял бы не более двенадцати-четырнадцати буферов. В данном случае, как нетрудно рассчитать, потребуется всего два цикла (192/96 == 2). Между циклами записи памяти мы разместим вычислительный цикл. Желательно спланировать его так, чтобы за время вычислений все буфера гарантированно успевали бы освободиться. Попутно отметим, если время вычислений значительно превосходит время выгрузки буферов, такую перегруппировку выполнять бессмысленно, т.к. в этом случае производительность в основном определяется скоростью вычислений, но не записью памяти.
Кстати, вычислительный цикл так же целесообразно разбить на две половинки, поместив первую из них перед циклом записи, а вторую позади него. Это гарантирует, что независимо от состояния буферов записи на момент начала выполнения записывающего цикла, все буфера будут действительно пусты. (Между прочим, этот факт не отмечен ни в одном известной мне инструкции по оптимизации, включая оригинальные руководства от Intel и AMD).
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
// выполняем часть запланированных вычислений,
// с таким расчетом, что бы буферам хватило времени
// на сброс их текущего содержимого, ведь отнюдь
// не факт, что на момент начала выполнения цикла
// буфера пусты
for(b = 0; b < 33; b++)
x += x/cos(x);
// выполняем 96 записей ячеек типа DWORD, что
// соответствует емкости буферов записи; к моменту
// завершения цикла практически все буфера будут
// забиты. "Практически" -потому что какая-то часть
// из них уже успеет выгрузится
for(a = 0; a < 96; a += 8)
{
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
// выполняем оставшуюся часть вычислений. Будет
// просто замечательно, если за это время все буфера
// успеют аккурат выгрузится, - тогда мы достигнет
// полного параллелизма!
for(b = 0; b < 33; b++)
x += x/cos(x);
// выполняем оставшиеся 96 записей. Поскольку они
// к этому моменту уже освободились, запись
// протекает так быстро, как это только возможно
for(a = 96; a < 192; a += 8)
{
p[a + 0] = (a+0);
p[a + 1] = (a+1);
p[a + 2] = (a+2);
p[a + 3] = (a+3);
p[a + 4] = (a+4);
p[a + 5] = (a+5);
p[a + 6] = (a+6);
p[a + 7] = (a+7);
}
Листинг 18 [Cache/write_sin.c] Оптимизированный вариант, комбинирующий запись в память с вычислительными операциями
Результаты прогона оптимизированного варианта программы не то, чтобы очень впечатляющие, но и скромными их никак не назовешь (см. рис. graph 0x012). И на P-III, и на AMD Athlon достигается приблизительно двукратный прирост производительности вне зависимости от того: находятся ли ячейки записываемой памяти в кэше первого уровня или нет.
Более пристальный осмотр показывает, что в каждой группы составляет по кр
Как мы помним, кэш-память процессоров P6 и AMD K6 не блокируемая, – т.е. один промах не препятствует другим попаданиям. записываемые в буфера, попадают в порядке завершения команд микрокода, но в
Процессоры P-II/P-III имеют 12 32х-байтовых буферов,
то операции записи в некэшируемую память следует группировать количеством не более двенадцати записи с шагом более 32х байт и девяносто шести при записи с шагом равным четырем (12х32/4).
Рассмотрим следующий пример:
// Инициализируем 20 некэшируемых элементов массива
for (a=0;a<20;a++)
p[a*32]=0x666;
// Выполняем некоторые вычисления
for (b=0;b<10;b++)
tmp=tmp*13;
Казалось бы разумно расщепить цикл инициализации на два, разделенных вычислительным циклом. Тогда, первые двенадцать итераций инициализационного цикла выполняются без задержек (записываемые данные направляются в буфера), а пока процессор обрабатывает вычислительный цикл, буфера выгружаются в память, и оставшиеся десять операций присвоения вновь выполняются без задержек!
for (a=0;a<12;a++)
p[a*32]=0x666;
for (b=0;b<10;b++)
tmp=tmp*13;
for (a=12;a<20;a++)
p[a*32]=0x666;
Теоретически оно, может быть, и так, но на практике сколь ни будь значительного выигрыша добиться не получается. Взгляните на рисунок ???, – видите, оптимизация увеличила производительность на единичные проценты. Это объясняется тем, что, во-первых, расщепление циклов увеличивает количество ветвлений, "съедая" тем самым львиную долю выигрыша (см. "Декодер - Ветвления"). А, во-вторых, пока процессор вычисляет новое значение параметра цикла, проверяет условие продолжения цикла, наконец, выполняет условный переход – буфера выгружаются в память.
Поэтому, расщеплять циклы подобные этому не надо – значительного прироста производительности это все равно не даст, а вот отлаживать программу станет труднее.
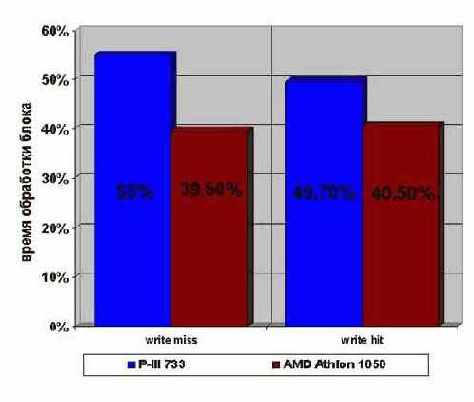
Рисунок 38 graph 0x012 Демонстрация эффективности комбинирования операций записи памяти с вычислительными операциями
Напоследок – две пары расщепленных циклов можно, безо всякого ущерба для производительности, объединить в один – super-цикл. Особенно это актуально для тех случаев, когда цикл записи памяти разбивается не на два, а на множество под – циклов. Тогда можно поступить так:
/*------------------------------------------------------------------------
*
* ОПТИМИЗИРОВАННЫЙ СВЕРНУТЫЙ ВАРИАНТ
*
------------------------------------------------------------------------*/
for(d = 0;d<192;d += 96)
{
for(b = 0; b < 33; b++)
x += x/cos(x);
for(a = d; a < d+96; a += 8)
{
p[a + 0] = (a + 0);
p[a + 1] = (a + 1);
p[a + 2] = (a + 2);
p[a + 3] = (a + 3);
p[a + 4] = (a + 4);
p[a + 5] = (a + 5);
p[a + 6] = (a + 6);
p[a + 7] = (a + 7);
}
}
Листинг 19 Объединение двух расщепленных циклов в один
А как быть, если алгоритмом предусматриваются одни лишь операции записи, и кроме них нет никаких других вычислений? Стоит ли "искусственно" внедрять какую-нибудь команду для задержки? Нет! В лучшем случае – при правильном планировании – код выполнится за то же самое время – не медленнее, но и не быстрее. И неудивительно – ведь во время выгрузки буферов процессор занят бесполезными вычислениями!