Кэш-подсистема современных процессоров
Кэш подсистема процессоров P-II, P-III, P-4 и AMDAthlon представляет собой многоуровневую иерархию, состоящую из следующих компонентов: кэша данных первого уровня, кэша команд первого уровня, общего кэша второго уровня, TLB-кэша страниц данных, TLB-кэша страниц кода, буфера упорядочивая записи и буферов записи (см. рис. 0х016).
MOB: Данные, сходящие с вычислительного конвейера, первым делом попадают на MOB (Memory Order Buffer – буфер упорядочивая записи к памяти) где они, постепенно накаливаясь, ожидают своей очереди выгрузки в паять. Грубо говоря, буфер упорядоченной записи играет тут же самую роль, что и зал ожидания в аэропорту. Пассажиры прибывают туда в более или менее случайном порядке, но улетают в строгом соответствии со временем, указанном в билете, да и то при условии, что к этому моменту выдастся летная погода и самолету предоставят "коридор" (кто летал – тот поймет).
Данные, находящиеся в MOB, всегда доступы процессору, даже если они еще не выгружены в память, однако емкость буфера упорядоченной записи довольно невелика (40 входов на P6) и при его переполнении вычислительный конвейер блокируется. Поэтому, содержимое MOB должно при всякой возможности незамедлительно выгружаться оттуда. Это происходит по крайней мере тремя путями:
а) если модифицируемая ячейка уже присутствует в кэш-памяти первого уровня, то она прямиком направляется в соответствующую ей кэш-строку, на что уходит всего один такт, в течении которого в кэш может быть записана одна или даже две любых несмежные ячейки (максимальное количество одновременно записываемых ячеек определяется архитектурой кэш-подсистемы конкретного процессора, –см "Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность. В кэше первого уровня");
б) если модифицируемая ячейка отсутствует в кэш-памяти первого уровня, она, при наличии хотя бы одного свободного буфера записи, попадает туда. Это так же занимает всего один такт, причем, максимальное количество параллельно записываемых ячеек определяется количеством портов, имеющихся в "распоряжении" у буферов записи (например, процессоры AMD K5 и Athlon содержат только один такой порт);
с) если модифицируемая ячейка отсутствует в кэш-памяти первого уровня и ни одного свободного буфера записи нет, – процессор самостоятельно загружает соответствующую копию данных в кэш-первого уровня, после чего переходит к пункту а). В зависимости от ряда обстоятельств, загрузка данных занимает от десятков до сотен (а то и десятков тысяч!) тактов процессора, поэтому, таких ситуаций по возможности следует избегать.
L1 CAHE. Кэш первого уровня размещается непосредственно на кристалле и реализуется на базе двух портовой статической памяти. Он состоит из двух независимых банков сверхоперативной памяти, каждый из которых управляется "своим" кэш-контроллером. Один кэширует машинные инструкции, другой – обрабатываемые ими данные. В кратной технической спецификации процессора обычно указывается суммарный объем кэш-памяти первого уровня, что приводит к некоторой неопределенности, т.к. емкости кэша инструкций и кэша данных не обязательно должны быть равны (а на последних процессорах они и не равны).
Каждый банк кэш-первого уровня помимо собственно данных и инструкций содержит и буфера ассоциативной трансляции (TLB) страниц данных и страниц кода соответственно. Под буфера ассоциативной трансляции отводятся фиксированные линейки кэша и занимаемое ими пространство "официально" исключено из емкости кэш-памяти. Т.е. если в спецификации сказано, что на процессоре установлен 8 Кб кэш данных, – все эти 8 Кб непосредственно доступны для кэширования данных, а реальная емкость кэш-памяти в действительности же превосходит 8 Кб.
Буфера Записи. Если честно, то у автора нет полной ясности где конкретно в кэш-иерархии расположены буфера записи. На блок-диаграммах процессоров Intel Pentium и AMD Athlon, приведенных в документации, они вообще отсутствуют, а в § 9.1 "INTERNAL CACHES, TLBS, AND BUFFERS" главы "MEMORY CACHE CONTROL" руководства по системному программирования от Intel, буфера записи изображены чисто условно и явно не в том месте, где им положено быть (сам Intel пишет, что "буфера записи связны с исполнительным блоком процессора", а на рисунке подсоединяет их к блоку интерфейсов с шиной – с каких это пор последний стал "вычислительным устройством"?!).
Проанализировав всю документированную информацию, так или иначе касающуюся буферов и основываясь на результат собственных экспериментов, автор склоняется к мысли, что буфера записи напрямую связаны как минимум с Буфером Упорядоченной Записи (ROB Wb), Блоком Интерфейса с Памятью (MIU) и Блоком Интерфейсов с Шиной (BIU). А на K5 (K6/Athlon) Буфера Записи связаны еще с кэш-памятью первого уровня.
Но, так или иначе, Буфера Записи позволяют на некоторое время откладывать фактическую запись в кэш и/или основную память, осуществляя эту операцию по мере освобождения кэш-контроллера, внутренней или системной шины, что ликвидирует целый ряд задержек и тем самым увеличивает производительность процессора.
Блок Интерфейсов с Памятью (MIU). Блок Интерфейсов с Памятью представляет собой одно из исполнительных устройств процессора и функционально состоит из двух компонентов: устройства чтения памяти и устройства записи памяти. Устройство чтения соединено с буферами записи и кэшем первого уровня. Если требуемая ячейка памяти присутствует хотя бы в одном из этих устройств, на ее чтение расходуется всего один такт. Причем независимо от типа обрабатываемых данных, вся кэш-линейка загружается целиком. Хотя Intel и AMD умалчивают об этой детали, она легко обнаруживается экспериментально. Действительно, имея всего одно устройство для работы с памятью, процессоры Pentium и AMD Athlon ухитряются спускать несколько инструкций чтения памяти за каждый такт, правда при условии, что данные выровнены по границе четырех байт и находятся в одной кэш-линейке. Отсюда следует, что шина, связывающая MIU и L1-Cache должна быть как минимум 256?битной, что (учитывая близость кэш-памяти первого уровня к ядру процессора) реализовать без особых затрат и труда.
Устройство записи памяти соединено с Блоком Упорядоченной Записи (ROB Wb), уже рассмотренным выше.
Блок Интерфейсов с Шиной Блок Интерфейсов с Шиной (BIU) является единственным звеном, связующим процессор с внешним миром, эдакое своеобразное "окно в Европу".
Сюда стекается все информация, вытесняемая из Буферов Записи и кэш-памяти первого уровня, сюда же поступают запросы за загрузку данных и машинных команд от кэша данных и кэша команд соответственно. Со стороны "Европы" к Блоку Интерфейсов с Шиной примыкает кэш-память второго уровня и основная оперативная память. Понятно, что от поворотливости BIU зависит быстродействие всей системы в целом.
Кэш второго уровня. В зависимости от конструктивных особенностей процессора кэш второго уровня может размещаться либо непосредственно на самом кристалле, либо монтироваться на отдельной плате вне его.
Однокристальная
(On Die) реализация обладает практически неограниченным быстродействием, – поскольку длины проводников, соединяющих кэш второго уровня с Блоком Интерфейсов с Шиной относительно невелики, кэш свободно работает на полной процессорной частоте, а разрядность его шины в процессорах P-III и P-4 достигает 256-бит. С другой стороны, такое решение значительно увеличивает площадь кристалла, а значит и его себестоимость (процент брака с увеличением площади кристалла растет экспоненциально). Тем не менее, благодаря совершенству производственных технологий (и не в последнюю очередь – жесточайшей конкурентной борьбе), – интегрированных кэшем второго уровня обладают все современные процессы.
Процессоры P-II и первые модели процессоров P-III и AMD Athlon имели
Двойная независимая шина (DIB – Dual Independent Bus). Для увеличения производительности системы, кэш второго уровня "общается" с BIU через свою собственную локальную шину, что значительно сокращает нагрузку, выпадающую на долю FSB.
В силу геометрической близости кэша второго уровня к процессорному ядру, длина локальной шины относительно невелика, а потому она может работать на значительно более высоких тактовых частотах, чем системная шина. Разрядность локальной шины долгое время оставалась равной разрядности системной шины и составляла 64 бита.
Впервые эта традиция нарушилась лишь с выходом Pentium-III Copper mine, оснащенным 256 битной локальной шиной, позволяющей загружать целую 32 байтную кэш-линейку всего за один такт! Это фактически уравняло кэш первого и кэш второго уровня в правах! (см. "Оптимизация обращения к памяти и кэшу. Влияние размера обрабатываемых данных на производительность. Особенности кэш-подсистемы процессоров P-II и P-III") К сожалению, процессоры AMD Athlon не могут похвастаться шириной своей шины…
Архитектура двойной независимой шины значительно снижает нагрузку на FSB, т.к. большая часть запросов к памяти обрабатывается локально. По статистике, коэффициент загрузки системной шины в однопроцессорных рабочих станциях, составляет порядка 10% от ее максимальной пропускной способности, а остальные 90% запросов ложатся на локальную шину. Даже в четырех процессорном сервере нагрузка на системную шину не превышает 60%, создавая тем самым обманчивую видимость, что производительность системной шины перестает быть самым узким местом системы, ограничивающим ее производительность.
Несмотря на то, что статистика не лжет, интерпретация казалось бы самоочевидных фактов, мягко говоря не совсем соответствует действительности. Низкая загрузка системной шины объясняется высокой латентностью основной оперативной памяти, приводящей к тому, что по меньшей мере половину времени шина тратит не на передачу, а на ожидание выполнения запроса. Помните как в анекдоте, – почему у вас нет черной икры? Да потому что спроса нет! К счастью, в старших моделях процессоров появились команды предвыборки, позволяющие предотвратить латентность и разогнать шину на всю мощь (см. так же "Оптимизация обращения к памяти и кэшу. Практическое использование предвыборки. Планирование дистанции предвыборки").
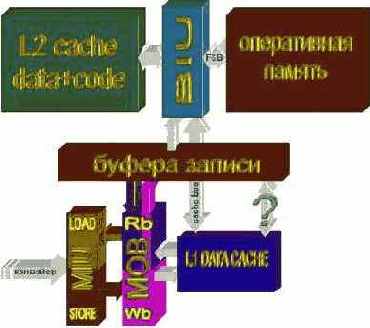
Рисунок 14 0х016 Кэш-подсистема современных процессоров (кэш кода не показан)
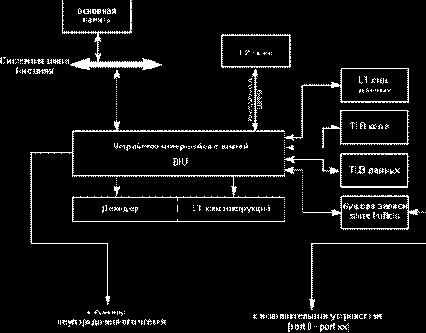
Рисунок 15 0x024 Блок-схема подсистемы кэш-памяти процессоров семейства Intel P6
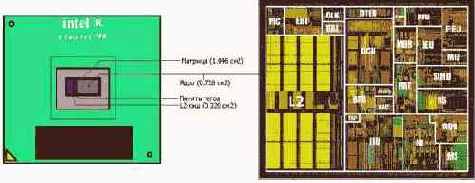
Рисунок 16 0x023 Физическое воплощение подсистемы кэш-памяти на примере процессора Intel Pentium-III Coppermain