Группировка операций чтения с операциями записи
В некоторых руководствах по оптимизации встречается утверждение о нежелательности перекрытия шинных транзакций чтения с транзакциями на запись. На самом деле, это утверждение неверно. Современные чипсеты, обладая способностью к внеочередной обработки запросов, самостоятельно определяют наиболее предпочтительную стратегию физического обмена с памятью. Поэтому, необходимости избегать смешивания команд чтения памяти с командами записи в действительности нет. Правда, за одним небольшим исключением. Сказанное справедливо исключительно для обработки больших массивов данных, многократно превышающих емкость кэш-памяти всех уровней. В противном случае, падение производительности на перекрывающихся транзакциях будет весьма значительным (см. "Кэш ???").
Пример, приведенный ниже, как раз и позволяет установить: как влияет перекрытие транзакций чтения/записи при обработке больших блоков данных.
/* -----------------------------------------------------------------------
перекрытия транзакций не происходит
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a += 4)
{
*(int *)((int)p1 + a) = x;
}
for (a = 0; a < BLOCK_SIZE; a += 4)
{
x += *(int *)((int)p1 + a);
}
/* -----------------------------------------------------------------------
перекрытия транзакций происходят постоянно
----------------------------------------------------------------------- */
for (a = 0; a < BLOCK_SIZE; a+= 32)
{
x += *(int *)((int)p1 + a);
*(int *)((int)p2 + a) =x;
}
Листинг 28 [Memory/read.write.c] Фрагмент программы, демонстрирующий влияние перекрытия транзакций чтения/записи на производительность
Опля! Вот уж чего мы вряд ли ожидали, – так это увеличения
производительности при перекрытии транзакций. Впрочем, даже поверхностное разбирательство показывает, что перекрытия транзакций тут играют второстепенную роль и изменения быстродействия вызваны ничем иным, как… разворотом цикла.
Действительно, совмещение двух циклов в одном равносильно его развороту на две итерации!
Чтобы компенсировать побочное влияние разворота, давайте развернем два непрерывающихся цикла на N итераций, а "гибридный" цикл – на N/2, причем, N должно быть достаточно велико, чтобы разворот в N/2 итерации был не сильно хуже, чем N (ведь на время прохождения трассы, как мы помним, влияет не только количество поворотов, но и протяженность прямых участков см. "Разворачивание циклов"). Достаточно точный результат достигается уже при N равном 16, вот его-то мы и возьмем (фрагмент программы с развернутыми циклами здесь не приводится, т.к. эту операцию вы должны уметь осуществлять и самостоятельно).
Ага, оказывается, что перекрытие транзакций все же уменьшает производительность. Правда, совсем не на много, всего лишь на ~5% на системе P-III 733/133/100/I815EP. Эта величина настолько мала, что в подавляющем большинстве случаев ей можно абсолютно безболезненно пренебречь. Правда, на AMD Athlon 1050/100/100/VIA KT133 проигрыш достигает аж ~25%, чем будет достаточно большой жертвой, но все-таки на нее можно закрыть глаза ради упрощения реализации вычислительного алгоритма.
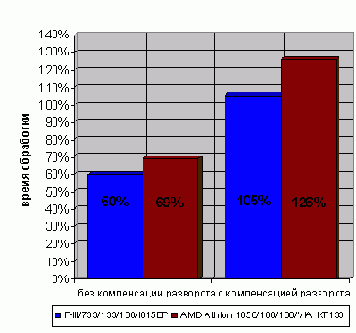
Рисунок 42 graph 31 Демонстрация влияния перекрытия транзакций чтения/записи на время обработки больших блоков данных с учета разворота цикла и без. Если на P-III перекрытие транзакций практически не влияет на производительность, то на AMD Athlon проигрыш уже становится ощутим, хотя и не так велик, что бы перечеркивать все выше написанное