Естественное (natural) выравнивание данных
Данные размером в байт, очевидно, никогда не пересекают кэш-строки, поэтому, никакого выравнивания для них и не требуется. Данные размером в слово, начинающиеся с четных
адресов, также гарантированно умещаются в одну кэш строку. Наконец, двойные слова, начинающиеся с адресов, делящихся на четыре без остатка, никогда не пересекают границу кэш-строк (см. рис. 0х026). Обобщив сказанное, мы получим следующую таблицу:
| размер данных | степень выравнивания | ||||||
| P-Plain, P MMX | P Pro, P-II, P-III | Athlon | |||||
| 1 байт (8 битов) | Произвольная | Произвольная | Произвольная | ||||
| 2 байта (16 битов) | Кратная 2 байтам | Кратная 2 байтам | Кратная 2 байтам | ||||
| 4 байта (32 бита) | Кратная 4 байтам | Кратная 4 байтам | Кратная 4 байтам | ||||
| 6 байт (48 бит) | Кратная 4 байтам | Кратная 8 байтам | Кратная 8 байтам | ||||
| 8 байтов (64 бита) | Кратная 8 байтам | Кратная 8 байтам | Кратная 8 байтам | ||||
| 10 байтов (80 битов) | Кратная 16 байтам | Кратная 16 байтам | Кратная 16 байтам | ||||
| 16 байтов (128 битов) | Кратная 16 байтам | Кратная 16 байтам | Кратная 16 байтам |
Таблица 4 Предпочтительная степень выравнивания для различных типов данных
Естественное выравнивание данных так же называют "выравниванием [для] перестраховщиков" или "выравниванием [для] бюрократов", поскольку оно исходит из худшего случая, когда выравниваемые данные пересекают обе кэш-линейки, не учитывая действительной ситуации. Платой за это становится увеличение количества потребляемой приложением памяти, что в ряде случает приводит к значительному падению производительности (в общем, за что боролись, на то и напоролись).
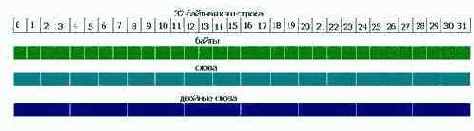
Рисунок 24 0х26 Естественное выравнивание данных